A video streaming platform like YouTube or Netflix must handle massive storage (hundreds of terabytes of daily uploads), complex multi-format transcoding, global CDN delivery with minimal buffering, and ML-driven recommendations that keep users engaged. The upload pipeline and the playback pipeline are effectively two separate systems with very different constraints — upload is a throughput-optimized batch processing problem; playback is a latency-optimized read path problem. Getting the boundary between these two right is the central design challenge.
- TCP over UDP for on-demand — retransmission eliminates packet-loss artifacts; UDP dominates live streaming where latency beats quality.
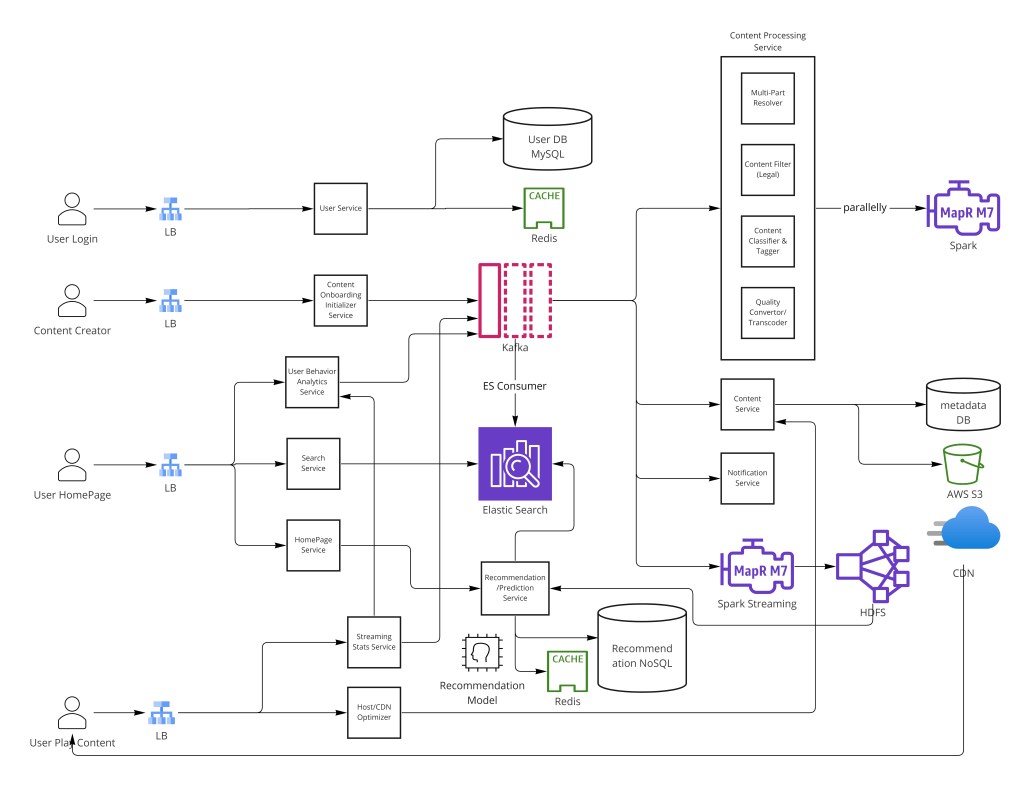
- Upload pipeline via Kafka — raw video fans out to content filtering, classification, and multi-resolution transcoding in parallel before landing in blob storage.
- HLS/DASH for ABR — video is split into 2–10 second segments at multiple bitrates; the client's ABR algorithm picks the quality tier that matches available bandwidth in real time.
- Blob storage (S3) + Cassandra — binary files in object storage; video metadata (fixed query patterns by ID) in Cassandra for high write throughput.
- CDN + lazy segment loading — serve only the segments being watched; dramatically cuts bandwidth and startup latency.
- Recommendations offline — pre-compute from Kafka-buffered watch signals; serve from key-value store at O(1) lookup.
- Redis cache-aside for auth — load on first miss; lazy loading avoids caching data that is never requested.
- Signed URLs for playback auth — time-limited tokens in CDN URLs prevent hotlinking and enforce access control without touching the video bytes.
Video uploads flow through a Kafka-backed pipeline of content filtering, classification, and multi-resolution transcoding before landing in blob storage and Cassandra metadata. Transcoded segments are served from geographically distributed CDNs using HLS/DASH adaptive bitrate streaming. Recommendations are computed offline and stored in key-value NoSQL. TCP is chosen over UDP for reliability — no packet loss means no buffering artifacts.
Step 1 — Clarify Requirements
Video streaming covers a wide surface area. In an interview, scope explicitly to avoid spending 45 minutes on a system you can't finish.
Functional
- User authentication (register and login).
- Video upload by content creators.
- Video processing: transcoding into multiple resolutions and formats.
- Video playback with adaptive bitrate streaming.
- Homepage with content discovery and personalized recommendations.
- Multi-platform support: web, mobile, TV; multiple resolutions (360p–4K); multiple regions and languages.
- Watch history and resume playback across devices.
Non-Functional
- Low latency, high availability — minimal buffering is the primary user experience metric; startup time under 2 seconds.
- High throughput storage — 100 TB of new video storage daily; petabyte-scale total library.
- Eventual consistency acceptable — a newly uploaded video appearing in search 30 seconds late is fine; a corrupted video is not.
- Durability — an uploaded video must never be silently lost after acknowledgement.
Step 2 — Capacity Estimation
Assume a large platform in the YouTube tier: 10 million daily active users (DAU), each watching ~10 videos per day; 1% are content creators uploading ~2 videos per day each.
Upload Volume
- Creators: 10M × 1% × 2 videos = 200,000 videos/day uploaded.
- Average raw video size: 500 MB → 200K × 500 MB = ~100 TB/day of raw ingest.
- After transcoding into 5 quality tiers (360p/480p/720p/1080p/4K), storage roughly triples → ~300 TB/day of processed segments added to the library.
- Sustained ingest: 100 TB/day ÷ 86,400 sec ≈ ~1.2 GB/sec of raw upload bandwidth to absorb.
Playback Volume
- 10M DAU × 10 videos × avg 10 min = 1 billion minutes/day of watch time.
- Average streaming bitrate ~2 Mbps → 1B min × 2 Mbps ÷ 8 = ~15 PB/day of video data served.
- 15 PB/day ÷ 86,400 sec ≈ ~1.7 Tbps of sustained CDN egress bandwidth — entirely consistent with YouTube's real-world numbers.
Storage Growth
- At 300 TB/day, the library grows by ~110 PB/year.
- Hot content (top 20% of videos) drives 80% of views — cache these at CDN edges; cold content serves from origin object store.
- Metadata: 200K videos/day × 365 × ~5 KB per record ≈ ~360 GB/year in Cassandra — trivially manageable.
Step 3 — API Design
Two distinct API surfaces: the upload API (write-heavy, async processing) and the playback API (read-heavy, latency-sensitive).
# Upload: initiate a resumable upload
POST /api/videos/upload/init
{ title, description, file_size_bytes, content_type }
→ { upload_id, upload_url } (pre-signed S3 URL)
# Upload: upload chunk (resumable, idempotent)
PUT {upload_url}
Content-Range: bytes 0-5242879/104857600
→ 308 Resume Incomplete | 200 OK (final chunk)
# Check processing status
GET /api/videos/{video_id}/status
→ { status: "processing"|"ready"|"failed", progress_pct }
# Playback: get video manifest
GET /api/videos/{video_id}/manifest
→ { hls_url, dash_url, thumbnail_url, duration_s, title }
# Playback: HLS master playlist (served from CDN)
GET https://cdn.example.com/v/{video_id}/master.m3u8
→ HLS playlist listing all quality variants with signed URLs
# Watch history / resume
POST /api/videos/{video_id}/progress
{ user_id, position_s, event: "pause"|"seek"|"complete" }
# Homepage feed
GET /api/feed?user_id=123&page_token=abc
→ { videos: [...], next_page_token }Two design choices worth calling out: upload uses resumable chunked upload (equivalent to Google's resumable upload protocol or AWS S3 multipart upload) so a mobile creator on a flaky connection can resume mid-upload without restarting. Playback returns a signed CDN URL in the manifest — the video bytes are served directly from CDN edge nodes, never through application servers.
Step 4 — Protocol: TCP vs. UDP vs. QUIC
YouTube and Netflix adopted TCP as the transport protocol primarily to guarantee video quality — TCP's retransmission ensures zero packet loss, eliminating the pixelation or blocking artifacts that dropped UDP packets cause. Security is a secondary benefit. The tradeoff is slightly higher latency compared to UDP, which is acceptable for on-demand streaming where a 2–10 second buffer absorbs jitter.
| Protocol | Latency | Reliability | Use case |
|---|---|---|---|
| TCP | Moderate | Guaranteed delivery, ordered | On-demand VOD streaming — quality beats latency |
| UDP | Low | Best-effort, may drop packets | Live streaming, video calls — latency beats quality |
| QUIC | Low (0-RTT) | Reliable over UDP, multiplexed streams | Emerging: YouTube uses it to reduce buffering on lossy networks |
| WebRTC | Very low | UDP-based, browser-native | Real-time 1:1 or small group video (Zoom, Meets) |
Google's QUIC protocol deserves a mention: it achieves TCP-like reliability over UDP, eliminates TCP head-of-line blocking across streams, and supports 0-RTT connection resumption. YouTube has been migrating to QUIC and reports measurable reductions in buffering events, especially on mobile networks with frequent IP address changes (handoffs between WiFi and cellular).
Step 5 — Upload Pipeline
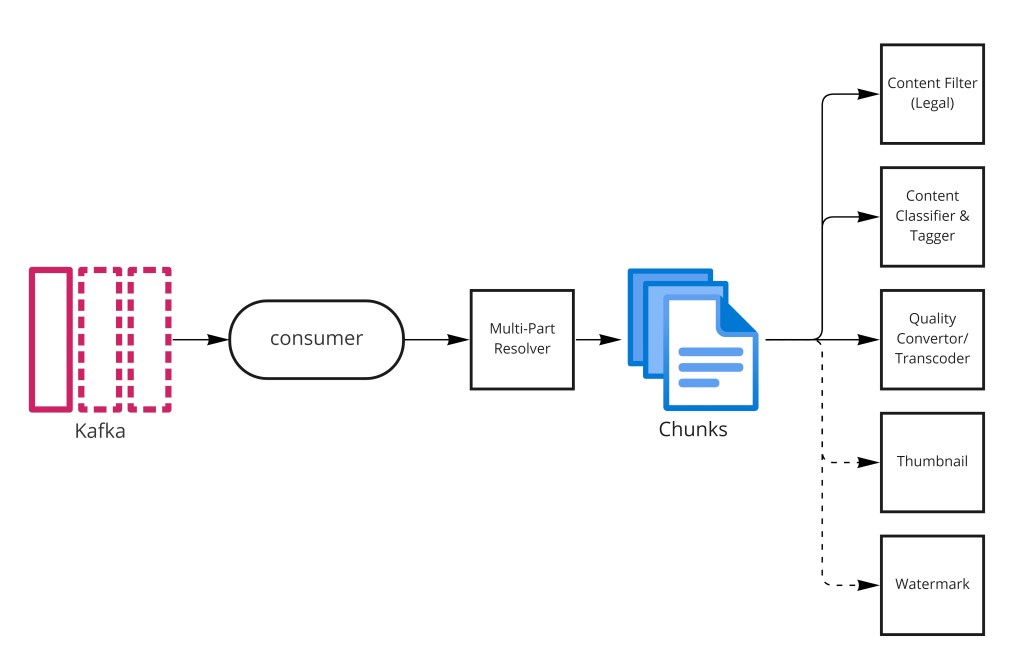
The upload path is the most complex flow in the system. A raw video file goes through multiple transformations before it is ready for viewers. The key design principle is fan-out through a message queue: as soon as the raw file lands in staging storage, a Kafka event triggers all downstream processing steps in parallel, so content filtering, classification, and transcoding all run concurrently rather than sequentially.
Creator uploads raw video (chunked, resumable)
→ Content Onboarding Initializer Service
- Validates file integrity (checksum)
- Writes PENDING record to Cassandra
- Moves raw file to staging S3 bucket
→ Publishes VideoUploaded event to Kafka
├── Multi-part Resolver: chunks file into ~5 min GOP segments
├── Content Filter: screens for illegal/inappropriate material
│ └── On violation: mark REJECTED, notify creator
├── Classifier & Tagger: generates tags, categories, language
│ └── ML model: visual + audio + transcript signals
└── Transcoder (parallel workers):
├── 360p H.264 ~400 Kbps
├── 480p H.264 ~800 Kbps
├── 720p H.264 ~2.5 Mbps
├── 1080p H.264 ~5 Mbps
└── 4K HEVC ~15 Mbps
└── Each resolution → segment files in S3
└── Content Service writes metadata to Cassandra
→ Elasticsearch indexing
→ Status: READYChunking the upload into parallel parts through the Multi-part Resolver dramatically reduces total processing time for large files. Each GOP (Group of Pictures) segment can be transcoded independently and in parallel across a fleet of transcoding workers. A 2-hour movie that takes 6 hours to transcode sequentially can be completed in under 30 minutes with enough parallel workers — critical for YouTube's promise of near-instant availability after upload.
Resumable Upload Implementation
On mobile networks, a 500 MB upload will almost certainly be interrupted. The resumable upload protocol uses pre-signed chunk URLs from S3 and tracks which chunks are confirmed in a Redis bitmap (indexed by chunk number). On reconnect, the client queries which chunks are already received and resumes from the first missing chunk. The server-side chunking state is stored in Redis with a TTL of 24 hours — after which an incomplete upload is abandoned.
Step 6 — Transcoding and ABR Streaming
Transcoding is the most resource-intensive step in the pipeline. The goal is to produce multiple quality representations of each video, split into short segments, formatted for adaptive bitrate (ABR) delivery.
HLS vs. DASH
| Protocol | Segment format | Manifest | Support |
|---|---|---|---|
| HLS (HTTP Live Streaming) | MPEG-TS or fMP4 | .m3u8 playlist | Native on iOS/macOS/Safari; widely supported |
| DASH (Dynamic Adaptive Streaming) | MP4 fragments (fMP4) | MPD XML manifest | Android, Chrome, smart TVs; not native on iOS |
In practice, large platforms transcode into both HLS and DASH to cover all client types. The segment files themselves (fMP4 chunks) can often be shared between HLS and DASH since both support fragmented MP4 — only the manifest files differ. Segment duration is typically 2–6 seconds: shorter segments allow faster quality switches but increase manifest overhead and the number of HTTP requests per minute of video.
ABR Algorithm
The client player implements an ABR (Adaptive Bitrate) algorithm that continuously monitors available bandwidth and buffer occupancy to select the optimal quality segment to fetch next. The two dominant approaches:
- Throughput-based ABR — measure the download speed of the last N segments; select the highest bitrate that fits within observed throughput with some headroom (e.g., 80% of measured bandwidth). Simple and widely deployed (HLS default).
- Buffer-based ABR (BBA) — select quality based purely on current buffer level: if the buffer is >30 seconds, step up quality; if <10 seconds, step down. More stable under bursty network conditions.
- Model Predictive Control (MPC) — Netflix's production algorithm; combines throughput prediction with buffer occupancy and optimizes over a horizon of future segments to minimize rebuffering probability while maximizing quality.
-- Buffer-based ABR (simplified)
FUNCTION select_next_quality(buffer_s, available_bitrates):
IF buffer_s > 30:
RETURN step_up(current_quality, available_bitrates)
ELIF buffer_s < 10:
RETURN step_down(current_quality, available_bitrates)
ELSE:
RETURN current_quality -- stable zone, hold current
-- Segment fetch loop
WHILE playing:
quality = select_next_quality(buffer.seconds_remaining(), bitrates)
segment_url = manifest.segment_url(next_segment_idx, quality)
fetch_async(segment_url) -- from CDN edge
next_segment_idx += 1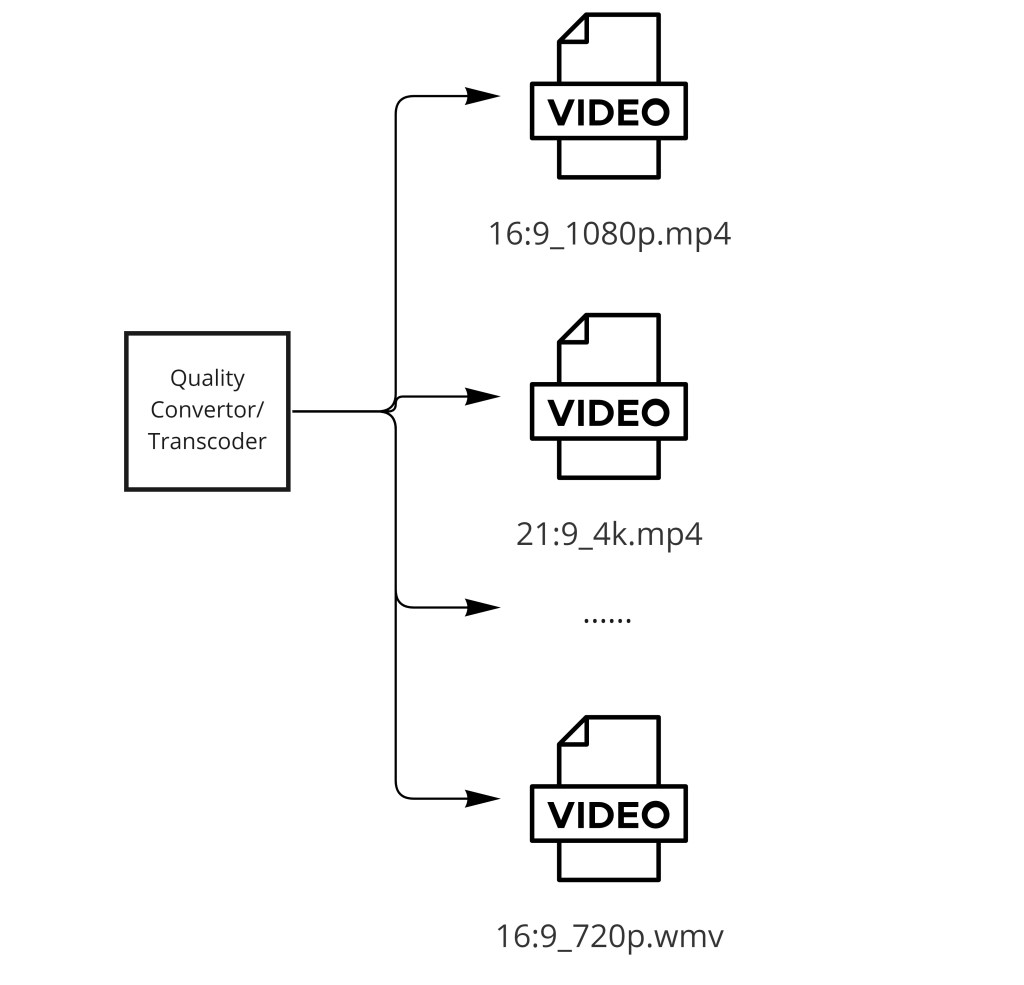
Step 7 — Data Model and Storage Architecture
Storage selection is driven by access patterns. Video streaming has a particularly sharp split: binary video segments belong in object storage; structured metadata belongs in a database.
| Data Type | Storage | Rationale |
|---|---|---|
| User accounts, billing | SQL (RDBMS) | ACID compliance for authentication and financial data |
| Video metadata | Cassandra (NoSQL) | High write throughput; fixed query patterns (by video ID, by creator) |
| Video segments | Blob storage (S3/GCS) | Object store purpose-built for large binary content at petabyte scale |
| Recommendations | Key-value NoSQL (DynamoDB/Redis) | Fast point lookups by user ID; updated via offline batch jobs |
| Search index | Elasticsearch | Full-text and fuzzy search with type-ahead |
| Watch progress | Cassandra | High write throughput (continuous position updates); keyed by (user_id, video_id) |
| Upload chunk state | Redis (TTL 24h) | Temporary, fast bitmap for tracking which chunks are confirmed |
Cassandra Data Model for Video Metadata
CREATE TABLE videos (
video_id UUID PRIMARY KEY,
creator_id UUID,
title TEXT,
description TEXT,
status TEXT, -- PENDING|PROCESSING|READY|FAILED
duration_s INT,
s3_prefix TEXT, -- base path in S3 for all segments
hls_manifest TEXT, -- CDN URL to master.m3u8
dash_manifest TEXT, -- CDN URL to manifest.mpd
thumbnail_url TEXT,
tags LIST<TEXT>,
created_at TIMESTAMP,
updated_at TIMESTAMP
);
-- Watch progress: (user, video) → last known position
CREATE TABLE watch_progress (
user_id UUID,
video_id UUID,
position_s INT,
updated_at TIMESTAMP,
PRIMARY KEY (user_id, video_id)
);Step 8 — User Authentication
The authentication flow uses a standard RESTful API service backed by a SQL database for ACID guarantees. A Redis cache with Cache-Aside (lazy loading) pattern sits in front of the SQL database: data is loaded into cache on first miss and served from cache on subsequent reads. Lazy loading is preferred over write-through here because it avoids caching data that is never actually requested — most user accounts are never queried after registration; only active session tokens matter for the hot path.
Session tokens are short-lived JWTs (15-minute access tokens + 7-day refresh tokens). On token refresh, the refresh token is validated against Redis (where active refresh tokens are stored) and a new access token is issued without touching the SQL database. This keeps the auth hot path entirely in Redis.
Step 9 — Content Delivery and Playback Authorization
Video files are served through a globally distributed CDN network. A Host Optimizer service directs each client to the nearest CDN node based on geographic proximity and current server load. The CDN layer applies lazy segment loading — only the segments the user is currently watching are fetched, rather than the full video file, reducing bandwidth costs and startup latency.
Playback Authorization with Signed URLs
Access control for video playback cannot rely on the CDN checking tokens on every segment request — that would saturate the application servers. Instead, the solution is CDN-signed URLs:
- Client authenticates to the application server and requests a video manifest.
- Application server generates a short-lived signed token (signed with a CDN-shared secret), embeds it in the manifest's segment URLs, and returns the manifest.
- Client fetches segments directly from CDN. The CDN validates the signature without any application server involvement — zero overhead on the hot path.
- Tokens expire after ~1 hour, preventing hotlinking and enforcing subscription validity.
-- Server-side: generate signed URL for a segment
FUNCTION sign_cdn_url(base_url, user_id, expires_at, secret):
policy = {
"url": base_url,
"user_id": user_id,
"exp": expires_at
}
signature = hmac_sha256(json_encode(policy), secret)
RETURN base_url + "?token=" + base64url(policy) + "&sig=" + signature
-- CDN edge: validate on each segment request
FUNCTION validate_cdn_request(request, secret):
policy, sig = parse_token(request.query.token, request.query.sig)
IF policy.exp < now(): RETURN 401
expected = hmac_sha256(json_encode(policy), secret)
IF sig != expected: RETURN 403
RETURN 200 -- serve the segmentStep 10 — Homepage, Search, and Recommendations
The homepage combines two data sources:
- Search Service — an Elasticsearch cluster with fuzzy search and type-ahead for active queries.
- Recommendations — pre-computed ML predictions stored in a key-value NoSQL database, keyed by user ID for O(1) lookup.
Recommendation Architecture
Recommendations are computed offline from watch history, watch duration, and interaction signals (likes, shares, re-watches, skips). These signals are fed into Kafka from the playback service and used to train recommendation models in batch. The architecture has two components:
- Candidate generation — a two-tower neural network retrieves ~hundreds of candidate videos from a pool of millions, based on user embedding similarity. The user tower encodes watch history; the video tower encodes video features. Fast approximate nearest-neighbor search (FAISS or ScaNN) retrieves top candidates.
- Ranking — a pointwise or pairwise ranking model (gradient boosted trees or a DNN) re-scores the candidates using richer features (context, time of day, device type, recency of video) to produce the final ranked list.
Pre-computed recommendations for each user are stored in DynamoDB keyed by user_id and refreshed every 1–6 hours by the offline batch pipeline. This gives O(1) lookup at serve time with no inference latency on the critical homepage path.
Step 11 — Playback Tracking
During playback, the client continuously logs watch status and position. This data flows into Kafka and drives multiple downstream consumers:
- Watch progress service — writes the current position to Cassandra so the user can resume from any device. Writes happen on pause, seek, and every 10 seconds during playback.
- Recommendation pipeline — offline processing of watch sessions to update user and video embeddings.
- Analytics service — real-time view counts, completion rates, and revenue attribution (for ad-supported content).
- CDN feedback loop — rebuffering events and segment download latencies are aggregated to identify CDN nodes with degraded performance and trigger rerouting.
Step 12 — Scaling, Fault Tolerance, and Live Streaming
Scaling the Transcoding Pipeline
Transcoding is CPU-intensive and naturally parallelizable. At 100 TB/day of ingest, the transcoding fleet must be elastic:
- Transcoding workers are stateless containers that pull jobs from a Kafka topic. Adding workers increases throughput linearly.
- Autoscaling is triggered by Kafka consumer lag — if the queue grows, spin up more workers; if it drains, scale back.
- GPU-accelerated transcoding (NVENC) can be 5–10× faster than CPU-only for H.264/HEVC; GPU instances are used for high-priority or high-resolution jobs.
- Each transcoding job is idempotent: a failed worker can be retried on a different node without duplicate output, because the output is keyed by
(video_id, quality, segment_index)and S3 puts are atomic.
CDN Fault Tolerance
- Manifest files include multiple CDN origin entries; the client player fails over to the next entry if a segment fetch times out.
- The Host Optimizer monitors CDN node health and removes degraded nodes from the selection pool.
- Origin shield: a tiered CDN architecture where a regional shield cache sits between edge nodes and the S3 origin, reducing origin load and single-region outage blast radius.
Live Streaming vs. VOD
| Dimension | VOD (on-demand) | Live streaming |
|---|---|---|
| Protocol | TCP (HLS/DASH) | UDP or QUIC (WebRTC for ultra-low latency) |
| Segment availability | All segments pre-generated | Segments generated in real time; manifest is rolling |
| CDN caching | High cache hit rate (same segments served many times) | Each segment is unique and expires after a few minutes |
| Transcoding | Offline, parallel, retryable | Real-time, single pass, must finish before segment deadline |
| Latency target | 2–10 sec startup OK | <3 sec for sports/events; <30 sec for standard live |
For live streaming, the transcoding path must process each GOP segment in real time with a strict deadline. A dedicated real-time transcoding cluster (distinct from the VOD fleet) handles live streams, using lower-latency encoding presets (faster but slightly lower quality) to meet the deadline. The rolling manifest is a special HLS/DASH variant (low-latency HLS) that publishes new segments every 0.5–2 seconds instead of the standard 2–6 seconds.
Key Tradeoffs
| Decision | Choice | Trade-off accepted |
|---|---|---|
| Transport protocol (VOD) | TCP (HLS/DASH) | Higher latency than UDP; acceptable because 2–10s buffer absorbs jitter |
| Recommendations | Offline pre-compute | Recommendations are 1–6 hours stale; catches most behavior changes |
| Video metadata store | Cassandra | No relational joins; query patterns must be known at schema design time |
| ABR segment length | 4–6 seconds | Shorter = faster quality switches but more HTTP requests and manifest overhead |
| Playback auth | CDN signed URLs | Token expiry means brief re-auth on very long sessions; app server not on hot path |
| Transcoding parallelism | GOP-parallel workers | Must ensure GOP boundaries align; slight overhead versus per-file sequential |
Video streaming is two systems: upload (complex multi-stage pipeline optimized for throughput, correctness, and parallel processing) and playback (optimized for latency via CDN, ABR, and lazy segment loading). TCP's no-packet-loss guarantee is worth the latency tradeoff for on-demand streaming. Recommendations belong offline — pre-compute once, serve fast from key-value store, retrain continuously from Kafka-buffered behavior signals. CDN signed URLs are the right way to enforce playback auth without application servers on the hot path.
Why TCP over UDP for on-demand video? TCP retransmission eliminates dropped-packet artifacts (pixelation, blocking); the slight latency increase is acceptable for buffered on-demand content because the player maintains a 2–10 second buffer. UDP is preferred for live streaming where low latency matters more than perfect quality.
Why store recommendations in a key-value store rather than computing them on-the-fly? Recommendation models are expensive to run; pre-computing offline and serving from a key-value store by user ID gives O(1) lookup with no inference latency on the critical path.
Why use Cassandra for video metadata? Queries are fixed-pattern (by video ID, by creator), write throughput is high (status updates, view count increments), and there are no relational joins needed — Cassandra's wide-column model is ideal.
How does ABR work? Video is split into 2–6 second segments at multiple bitrates. The client's ABR algorithm monitors buffer occupancy and measured throughput, selecting the highest quality tier that can be downloaded without rebuffering.
How do you authorize video playback without overloading application servers? Use CDN-signed URLs embedded in the manifest. The CDN validates the HMAC signature at the edge without any application server involvement — auth happens once at manifest fetch time, not on every segment.