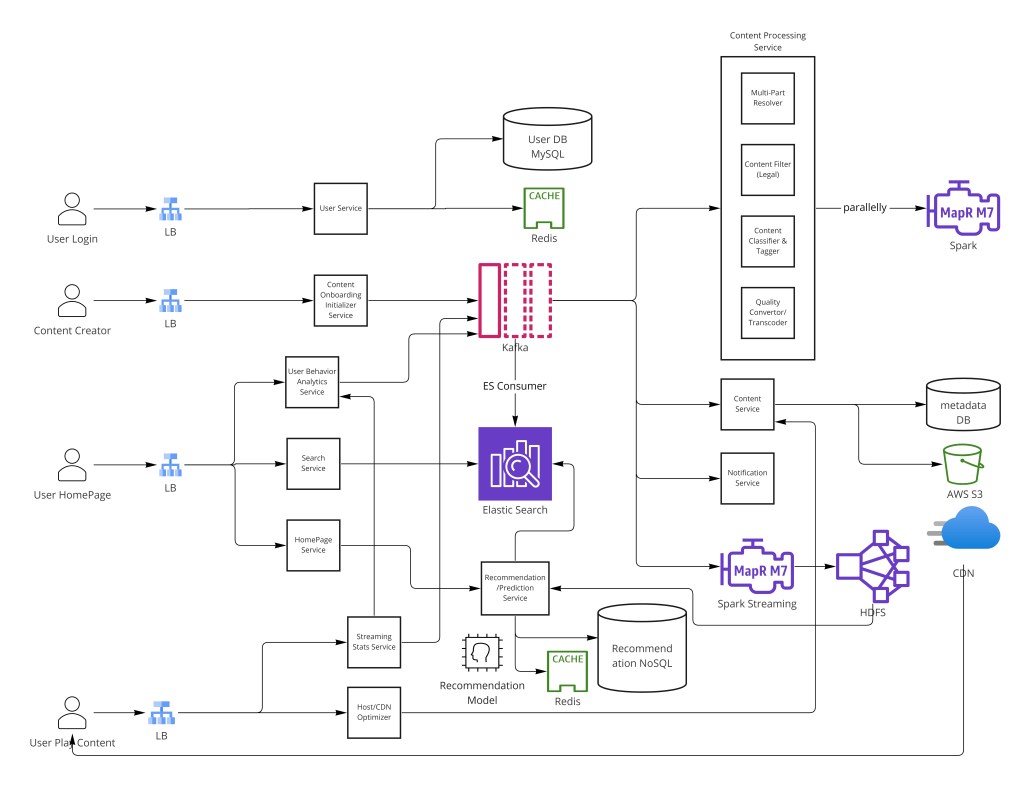
像 YouTube 或 Netflix 这样的视频流平台必须处理海量存储(每天数百 TB 上传)、复杂的多格式转码、最小缓冲的全球 CDN 投递,以及让用户保持参与的 ML 驱动推荐。上传管道和播放管道实际是两个有很不同约束的独立系统——上传是吞吐优化的批处理问题;播放是延迟优化的读路径问题。把这两者间的边界做对是核心设计挑战。
- 点播用 TCP 而非 UDP——重传消除丢包伪影;UDP 主导延迟胜过质量的直播。
- 经 Kafka 的上传管道——原始视频扇出到内容过滤、分类和多分辨率转码并行,再落进 blob 存储。
- HLS/DASH 做 ABR——视频被切成多码率的 2–10 秒段;客户端 ABR 算法实时挑匹配可用带宽的质量层。
- Blob 存储(S3)+ Cassandra——二进制文件在对象存储;视频元数据(按 ID 的固定查询模式)在 Cassandra 求高写吞吐。
- CDN + 惰性段加载——只服务正在观看的段;大幅削减带宽和启动延迟。
- 推荐离线——从 Kafka 缓冲的观看信号预计算;从键值存储 O(1) 查找服务。
- 认证用 Redis cache-aside——首次未命中时加载;懒加载避免缓存从不被请求的数据。
- 播放认证用签名 URL——CDN URL 里的限时 token 防盗链并强制访问控制而不碰视频字节。
视频上传流经一个 Kafka 支撑的内容过滤、分类和多分辨率转码管道,再落进 blob 存储和 Cassandra 元数据。转码段用 HLS/DASH 自适应码率流从地理分布的 CDN 服务。推荐离线计算并存在键值 NoSQL。TCP 被选过 UDP 求可靠——无丢包意味无缓冲伪影。
第 1 步 — 澄清需求
视频流覆盖很广的面。面试中显式界定以免花 45 分钟在一个你做不完的系统上。
功能
- 用户认证(注册和登录)。
- 内容创作者上传视频。
- 视频处理:转码成多分辨率和格式。
- 带自适应码率流的视频播放。
- 带内容发现和个性化推荐的首页。
- 多平台支持:web、移动、TV;多分辨率(360p–4K);多区域和语言。
- 观看历史和跨设备续播。
非功能
- 低延迟、高可用——最小缓冲是主要用户体验指标;启动时间 2 秒内。
- 高吞吐存储——每天 100 TB 新视频存储;PB 级总库。
- 最终一致可接受——新上传视频在搜索里晚 30 秒出现没问题;损坏视频不行。
- 持久性——已上传视频在确认后绝不能被静默丢失。
第 2 步 — 容量估算
假设一个 YouTube 量级的大平台:1000 万日活(DAU),每个每天看 ~10 个视频;1% 是内容创作者,各每天上传 ~2 个视频。
上传量
- 创作者:10M × 1% × 2 视频 = 每天 200,000 个视频上传。
- 平均原始视频大小:500 MB → 200K × 500 MB = ~100 TB/天原始摄取。
- 转码成 5 个质量层(360p/480p/720p/1080p/4K)后,存储大致三倍 → 库每天加 ~300 TB/天处理后的段。
- 持续摄取:100 TB/天 ÷ 86,400 秒 ≈ ~1.2 GB/秒要吸收的原始上传带宽。
播放量
- 10M DAU × 10 视频 × 平均 10 分钟 = 10 亿分钟/天观看时间。
- 平均流码率 ~2 Mbps → 1B 分钟 × 2 Mbps ÷ 8 = ~15 PB/天视频数据服务。
- 15 PB/天 ÷ 86,400 秒 ≈ ~1.7 Tbps持续 CDN egress 带宽——完全符合 YouTube 真实数字。
存储增长
- 每天 300 TB,库每年增长 ~110 PB。
- 热门内容(前 20% 视频)驱动 80% 观看——在 CDN 边缘缓存这些;冷内容从源对象存储服务。
- 元数据:200K 视频/天 × 365 × 每条 ~5 KB ≈ Cassandra 里 ~360 GB/年——平凡可管理。
第 3 步 — API 设计
两个不同的 API 面:上传 API(写多、异步处理)和播放 API(读多、延迟敏感)。
# 上传:发起一个可恢复上传
POST /api/videos/upload/init
{ title, description, file_size_bytes, content_type }
→ { upload_id, upload_url }(预签名 S3 URL)
# 上传:上传块(可恢复、幂等)
PUT {upload_url}
Content-Range: bytes 0-5242879/104857600
→ 308 Resume Incomplete | 200 OK(最后一块)
# 检查处理状态
GET /api/videos/{video_id}/status
→ { status: "processing"|"ready"|"failed", progress_pct }
# 播放:获取视频 manifest
GET /api/videos/{video_id}/manifest
→ { hls_url, dash_url, thumbnail_url, duration_s, title }
# 播放:HLS 主播放列表(从 CDN 服务)
GET https://cdn.example.com/v/{video_id}/master.m3u8
→ 列出所有质量变体带签名 URL 的 HLS 播放列表
# 观看历史 / 续播
POST /api/videos/{video_id}/progress
{ user_id, position_s, event: "pause"|"seek"|"complete" }
# 首页 feed
GET /api/feed?user_id=123&page_token=abc
→ { videos: [...], next_page_token }两个值得指出的设计选择:上传用可恢复分块上传(等价于 Google 的可恢复上传协议或 AWS S3 multipart 上传),使不稳定连接的移动创作者能在上传中途恢复而不重启。播放在 manifest 里返回签名 CDN URL——视频字节直接从 CDN 边缘节点服务,从不经应用服务器。
第 4 步 — 协议:TCP vs UDP vs QUIC
YouTube 和 Netflix 采用 TCP 作传输协议主要为保证视频质量——TCP 的重传确保零丢包,消除丢失 UDP 包造成的像素化或块状伪影。安全是次要好处。取舍是相比 UDP 略高的延迟,对点播流可接受,因为 2–10 秒缓冲吸收抖动。
| 协议 | 延迟 | 可靠性 | 用例 |
|---|---|---|---|
| TCP | 中等 | 保证投递、有序 | 点播 VOD 流——质量胜过延迟 |
| UDP | 低 | 尽力而为、可能丢包 | 直播、视频通话——延迟胜过质量 |
| QUIC | 低(0-RTT) | UDP 上可靠、多路复用流 | 新兴:YouTube 用它在有损网络降低缓冲 |
| WebRTC | 极低 | 基于 UDP、浏览器原生 | 实时 1:1 或小组视频(Zoom、Meets) |
Google 的 QUIC 协议值得一提:它在 UDP 上实现类 TCP 可靠性、消除跨流的 TCP 队头阻塞,并支持 0-RTT 连接恢复。YouTube 一直在迁移到 QUIC 并报告可测量的缓冲事件减少,尤其在频繁 IP 地址变化(WiFi 和蜂窝间切换)的移动网络。
第 5 步 — 上传管道
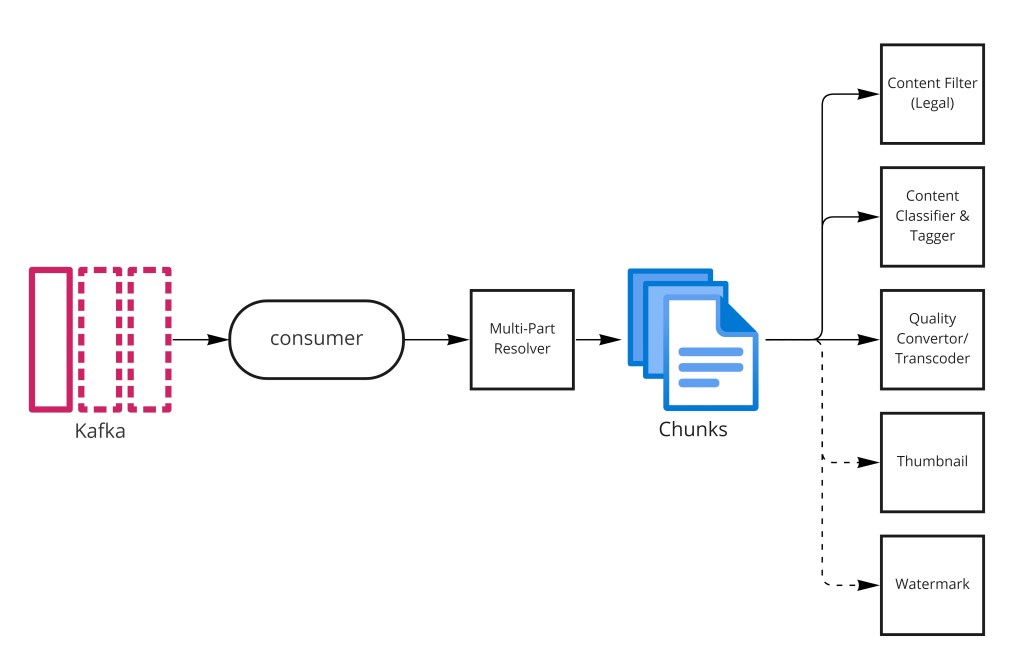
上传路径是系统里最复杂的流程。原始视频文件在准备好供观众观看前经过多个转换。关键设计原则是经消息队列扇出:原始文件一落进暂存存储,一个 Kafka 事件就并行触发所有下游处理步骤,使内容过滤、分类和转码全部并发运行而非顺序。
创作者上传原始视频(分块、可恢复)
→ 内容入驻初始化服务
- 校验文件完整性(校验和)
- 写 PENDING 记录到 Cassandra
- 把原始文件移到暂存 S3 桶
→ 发布 VideoUploaded 事件到 Kafka
├── Multi-part Resolver: 把文件切成 ~5 分钟 GOP 段
├── 内容过滤: 筛查非法/不当材料
│ └── 违规时: 标 REJECTED,通知创作者
├── 分类与打标: 生成标签、分类、语言
│ └── ML 模型: 视觉 + 音频 + 转录信号
└── 转码器(并行 worker):
├── 360p H.264 ~400 Kbps
├── 480p H.264 ~800 Kbps
├── 720p H.264 ~2.5 Mbps
├── 1080p H.264 ~5 Mbps
└── 4K HEVC ~15 Mbps
└── 每个分辨率 → S3 里的段文件
└── 内容服务写元数据到 Cassandra
→ Elasticsearch 索引
→ 状态: READY经 Multi-part Resolver 把上传切成并行部分,大幅减少大文件的总处理时间。每个 GOP(Group of Pictures)段能在一群转码 worker 上独立并行转码。一部顺序转码要 6 小时的 2 小时电影,有足够并行 worker 能在 30 分钟内完成——对 YouTube 承诺上传后近乎即时可用至关重要。
可恢复上传实现
移动网络上,500 MB 上传几乎肯定会被打断。可恢复上传协议用来自 S3 的预签名块 URL,并在一个 Redis 位图(按块号索引)里跟踪哪些块已确认。重连时,客户端查哪些块已收到并从第一个缺失块恢复。服务端分块状态存在 Redis 带 24 小时 TTL——之后未完成上传被放弃。
第 6 步 — 转码与 ABR 流
转码是管道里最资源密集的步骤。目标是产生每个视频的多个质量表示,切成短段,为自适应码率(ABR)投递格式化。
HLS vs DASH
| 协议 | 段格式 | Manifest | 支持 |
|---|---|---|---|
| HLS (HTTP Live Streaming) | MPEG-TS 或 fMP4 | .m3u8 播放列表 | iOS/macOS/Safari 原生;广泛支持 |
| DASH (Dynamic Adaptive Streaming) | MP4 片段(fMP4) | MPD XML manifest | Android、Chrome、智能 TV;iOS 不原生 |
实践中,大平台转码成 HLS 和 DASH 两者以覆盖所有客户端类型。段文件本身(fMP4 块)常能在 HLS 和 DASH 间共享,因为两者都支持碎片化 MP4——只有 manifest 文件不同。段时长通常 2–6 秒:更短的段允许更快质量切换但增加 manifest 开销和每分钟视频的 HTTP 请求数。
ABR 算法
客户端播放器实现一个 ABR(自适应码率)算法,持续监控可用带宽和缓冲占用以选下一个要取的最优质量段。两个主导方法:
- 基于吞吐的 ABR——测量最后 N 个段的下载速度;选适配观测吞吐带些余量(如观测带宽的 80%)的最高码率。简单且广泛部署(HLS 默认)。
- 基于缓冲的 ABR(BBA)——纯基于当前缓冲级别选质量:若缓冲 >30 秒,升级质量;若 <10 秒,降级。突发网络条件下更稳定。
- 模型预测控制(MPC)——Netflix 的生产算法;结合吞吐预测与缓冲占用,在未来段的视界上优化以最小化重缓冲概率同时最大化质量。
-- 基于缓冲的 ABR(简化)
FUNCTION select_next_quality(buffer_s, available_bitrates):
IF buffer_s > 30:
RETURN step_up(current_quality, available_bitrates)
ELIF buffer_s < 10:
RETURN step_down(current_quality, available_bitrates)
ELSE:
RETURN current_quality -- 稳定区,保持当前
-- 段取循环
WHILE playing:
quality = select_next_quality(buffer.seconds_remaining(), bitrates)
segment_url = manifest.segment_url(next_segment_idx, quality)
fetch_async(segment_url) -- 从 CDN 边缘
next_segment_idx += 1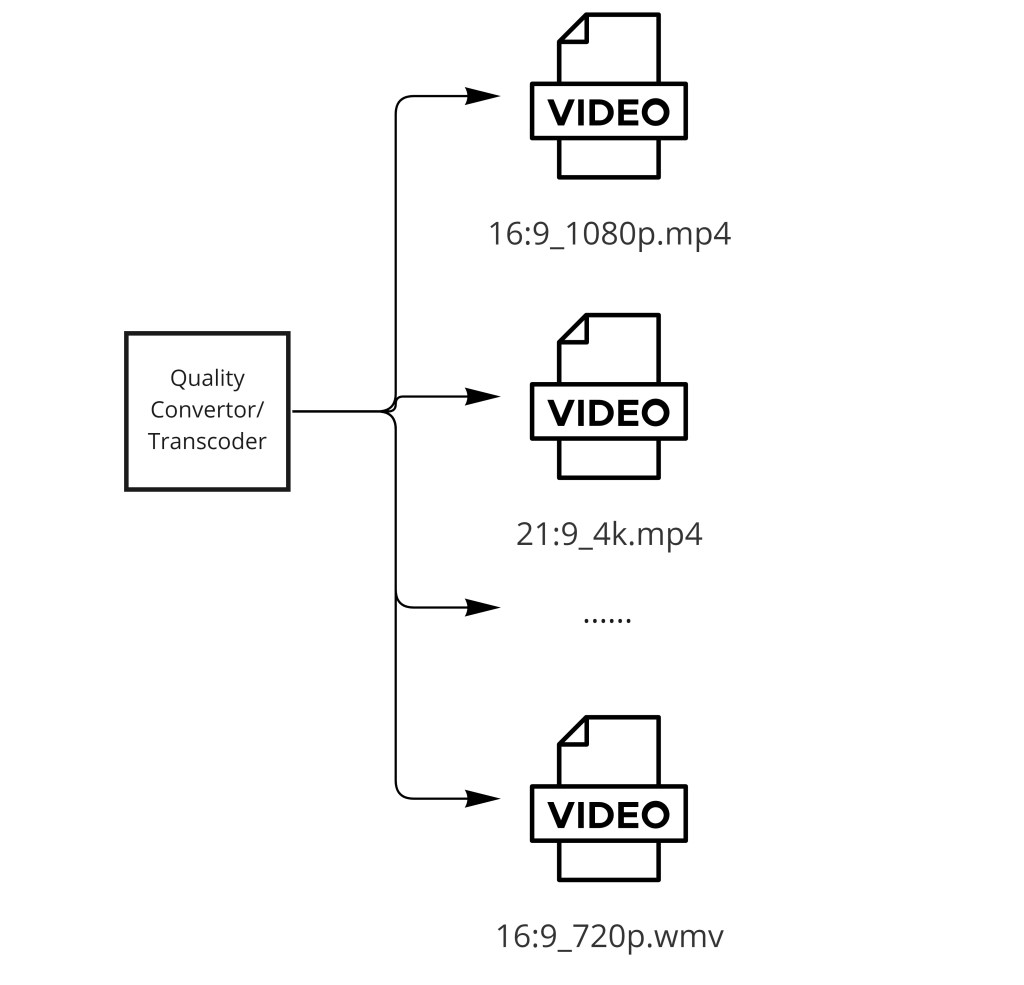
第 7 步 — 数据模型与存储架构
存储选择由访问模式驱动。视频流有一个特别鲜明的拆分:二进制视频段属于对象存储;结构化元数据属于数据库。
| 数据类型 | 存储 | 理由 |
|---|---|---|
| 用户账户、计费 | SQL (RDBMS) | 认证和金融数据的 ACID 合规 |
| 视频元数据 | Cassandra (NoSQL) | 高写吞吐;固定查询模式(按视频 ID、按创作者) |
| 视频段 | Blob 存储 (S3/GCS) | 为 PB 级大二进制内容专建的对象存储 |
| 推荐 | 键值 NoSQL (DynamoDB/Redis) | 按用户 ID 快速点查;经离线批作业更新 |
| 搜索索引 | Elasticsearch | 带 type-ahead 的全文和模糊搜索 |
| 观看进度 | Cassandra | 高写吞吐(持续位置更新);按 (user_id, video_id) 为键 |
| 上传块状态 | Redis (TTL 24h) | 临时、快速的位图跟踪哪些块已确认 |
视频元数据的 Cassandra 数据模型
CREATE TABLE videos (
video_id UUID PRIMARY KEY,
creator_id UUID,
title TEXT,
description TEXT,
status TEXT, -- PENDING|PROCESSING|READY|FAILED
duration_s INT,
s3_prefix TEXT, -- S3 里所有段的基础路径
hls_manifest TEXT, -- 到 master.m3u8 的 CDN URL
dash_manifest TEXT, -- 到 manifest.mpd 的 CDN URL
thumbnail_url TEXT,
tags LIST<TEXT>,
created_at TIMESTAMP,
updated_at TIMESTAMP
);
-- 观看进度: (user, video) → 最后已知位置
CREATE TABLE watch_progress (
user_id UUID,
video_id UUID,
position_s INT,
updated_at TIMESTAMP,
PRIMARY KEY (user_id, video_id)
);第 8 步 — 用户认证
认证流程用一个由 SQL 数据库支撑求 ACID 保证的标准 RESTful API 服务。一个带 Cache-Aside(懒加载)模式的 Redis 缓存坐在 SQL 数据库前:数据在首次未命中时加载进缓存、后续读从缓存服务。这里懒加载优于 write-through,因为它避免缓存从不实际被请求的数据——大多数用户账户在注册后从不被查;只有活跃会话 token 对热路径要紧。
会话 token 是短命 JWT(15 分钟访问 token + 7 天刷新 token)。token 刷新时,刷新 token 对照 Redis(活跃刷新 token 存那)校验,并签发一个新访问 token 而不碰 SQL 数据库。这让认证热路径完全在 Redis 里。
第 9 步 — 内容投递与播放授权
视频文件经一个全球分布的 CDN 网络服务。一个 Host Optimizer 服务基于地理邻近和当前服务器负载把每个客户端导向最近的 CDN 节点。CDN 层应用惰性段加载——只取用户当前观看的段,而非完整视频文件,减少带宽成本和启动延迟。
用签名 URL 做播放授权
视频播放的访问控制不能依赖 CDN 在每个段请求检查 token——那会饱和应用服务器。相反,解法是 CDN 签名 URL:
- 客户端向应用服务器认证并请求一个视频 manifest。
- 应用服务器生成一个短命签名 token(用 CDN 共享 secret 签名)、把它嵌进 manifest 的段 URL,并返回 manifest。
- 客户端直接从 CDN 取段。CDN 验证签名而无任何应用服务器参与——热路径上零开销。
- token ~1 小时后过期,防止盗链并强制订阅有效性。
-- 服务端:为一个段生成签名 URL
FUNCTION sign_cdn_url(base_url, user_id, expires_at, secret):
policy = {
"url": base_url,
"user_id": user_id,
"exp": expires_at
}
signature = hmac_sha256(json_encode(policy), secret)
RETURN base_url + "?token=" + base64url(policy) + "&sig=" + signature
-- CDN 边缘:对每个段请求验证
FUNCTION validate_cdn_request(request, secret):
policy, sig = parse_token(request.query.token, request.query.sig)
IF policy.exp < now(): RETURN 401
expected = hmac_sha256(json_encode(policy), secret)
IF sig != expected: RETURN 403
RETURN 200 -- 服务该段第 10 步 — 首页、搜索与推荐
首页结合两个数据源:
- 搜索服务——一个带模糊搜索和 type-ahead 的 Elasticsearch 集群用于主动查询。
- 推荐——预计算的 ML 预测存在键值 NoSQL 数据库,按用户 ID 为键做 O(1) 查找。
推荐架构
推荐从观看历史、观看时长和交互信号(点赞、分享、重看、跳过)离线计算。这些信号从播放服务喂进 Kafka 并用于批量训练推荐模型。架构有两个组件:
- 候选生成——一个双塔神经网络基于用户嵌入相似度从数百万池子检索 ~数百个候选视频。用户塔编码观看历史;视频塔编码视频特征。快速近似最近邻搜索(FAISS 或 ScaNN)检索 top 候选。
- 排序——一个 pointwise 或 pairwise 排序模型(梯度提升树或 DNN)用更丰富特征(上下文、时段、设备类型、视频新近度)重新给候选评分以产生最终排序列表。
每个用户的预计算推荐存在 DynamoDB,按 user_id 为键,由离线批管道每 1–6 小时刷新。这在服务时给 O(1) 查找,关键首页路径上无推理延迟。
第 11 步 — 播放跟踪
播放期间,客户端持续记录观看状态和位置。这数据流入 Kafka 并驱动多个下游消费者:
- 观看进度服务——把当前位置写到 Cassandra,使用户能从任何设备续播。写在暂停、seek 和播放期间每 10 秒发生。
- 推荐管道——观看会话的离线处理以更新用户和视频嵌入。
- 分析服务——实时观看计数、完成率和收入归因(广告支持内容)。
- CDN 反馈循环——重缓冲事件和段下载延迟被聚合以识别性能退化的 CDN 节点并触发重路由。
第 12 步 — 扩展、容错与直播
扩展转码管道
转码 CPU 密集且自然可并行。在每天 100 TB 摄取,转码机群必须弹性:
- 转码 worker 是从 Kafka topic 拉作业的无状态容器。加 worker 线性增加吞吐。
- 自动扩缩由 Kafka 消费者 lag 触发——若队列增长,开更多 worker;若排干,缩回。
- GPU 加速转码(NVENC)对 H.264/HEVC 能比纯 CPU 快 5–10×;GPU 实例用于高优先级或高分辨率作业。
- 每个转码作业幂等:失败 worker 能在另一节点重试而无重复输出,因为输出按
(video_id, quality, segment_index)为键且 S3 put 原子。
CDN 容错
- Manifest 文件含多个 CDN 源条目;若段取超时客户端播放器故障转移到下一条目。
- Host Optimizer 监控 CDN 节点健康并把退化节点从选择池移除。
- 源屏蔽(origin shield):一个分层 CDN 架构,区域屏蔽缓存坐在边缘节点和 S3 源之间,减少源负载和单区域宕机爆炸半径。
直播 vs VOD
| 维度 | VOD(点播) | 直播 |
|---|---|---|
| 协议 | TCP (HLS/DASH) | UDP 或 QUIC(超低延迟用 WebRTC) |
| 段可用性 | 所有段预生成 | 段实时生成;manifest 滚动 |
| CDN 缓存 | 高缓存命中率(同样段服务多次) | 每个段唯一且几分钟后过期 |
| 转码 | 离线、并行、可重试 | 实时、单遍、必须在段截止前完成 |
| 延迟目标 | 2–10 秒启动 OK | 体育/活动 <3 秒;标准直播 <30 秒 |
对直播,转码路径必须以严格截止实时处理每个 GOP 段。一个专用实时转码集群(区别于 VOD 机群)处理直播流,用更低延迟编码预设(更快但质量略低)以满足截止。滚动 manifest 是一个特殊 HLS/DASH 变体(低延迟 HLS),每 0.5–2 秒发布新段而非标准的 2–6 秒。
关键取舍
| 决策 | 选择 | 接受的取舍 |
|---|---|---|
| 传输协议(VOD) | TCP (HLS/DASH) | 比 UDP 更高延迟;可接受因为 2–10s 缓冲吸收抖动 |
| 推荐 | 离线预计算 | 推荐 1–6 小时陈旧;抓住大多数行为变化 |
| 视频元数据存储 | Cassandra | 无关系 join;查询模式必须在 schema 设计时已知 |
| ABR 段长 | 4–6 秒 | 更短 = 更快质量切换但更多 HTTP 请求和 manifest 开销 |
| 播放认证 | CDN 签名 URL | token 过期意味很长会话上短暂重认证;应用服务器不在热路径 |
| 转码并行 | GOP 并行 worker | 必须确保 GOP 边界对齐;相比每文件顺序略有开销 |
视频流是两个系统:上传(为吞吐、正确性和并行处理优化的复杂多阶段管道)和播放(经 CDN、ABR 和惰性段加载为延迟优化)。TCP 的无丢包保证对点播流值得那个延迟取舍。推荐属于离线——预计算一次、从键值存储快速服务、从 Kafka 缓冲的行为信号持续重训。CDN 签名 URL 是强制播放授权而不让应用服务器在热路径上的正确方式。
点播视频为什么 TCP 而非 UDP?TCP 重传消除丢包伪影(像素化、块状);略增的延迟对缓冲的点播内容可接受,因为播放器维护 2–10 秒缓冲。UDP 对低延迟比完美质量更要紧的直播更受偏好。
为什么把推荐存在键值存储而非即时计算?推荐模型运行昂贵;离线预计算并按用户 ID 从键值存储服务给 O(1) 查找,关键路径上无推理延迟。
为什么视频元数据用 Cassandra?查询固定模式(按视频 ID、按创作者)、写吞吐高(状态更新、观看计数自增),且无需关系 join——Cassandra 的宽列模型理想。
ABR 怎么工作?视频被切成多码率的 2–6 秒段。客户端 ABR 算法监控缓冲占用和测量吞吐,选能无重缓冲下载的最高质量层。
怎么授权视频播放而不过载应用服务器?用嵌在 manifest 里的 CDN 签名 URL。CDN 在边缘验证 HMAC 签名而无任何应用服务器参与——认证在 manifest 取时发生一次,而非每个段。