Data models are the most consequential decision in any system. They shape not only how software is written, but how we think about the problem at all. Chapter 2 surveys the three dominant families — relational, document, and graph — and examines the query languages that each naturally pairs with.
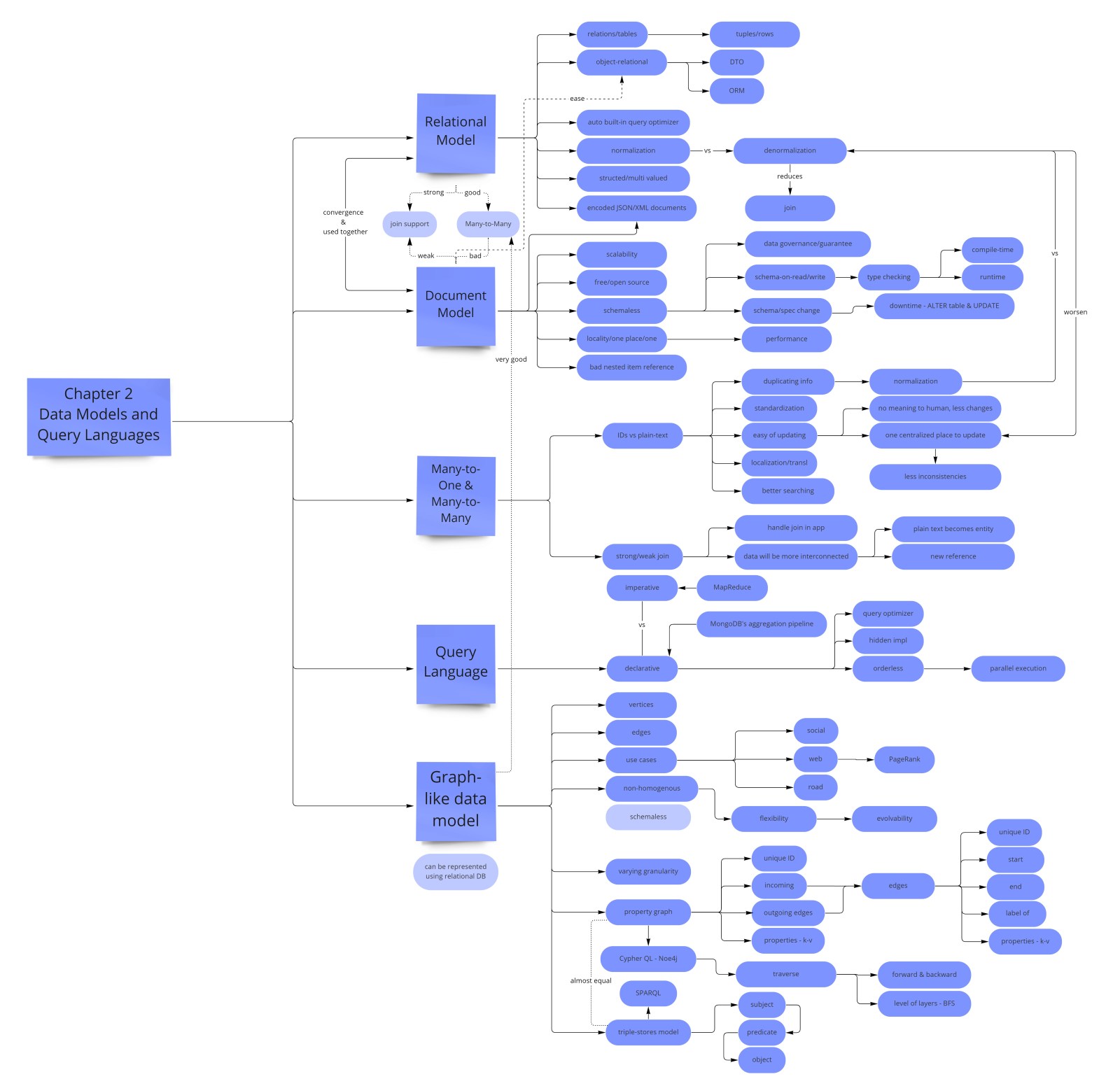
- Relational model (1970, Codd) — data as tables of tuples; SQL is declarative; the query optimizer picks the access path. Best for many-to-many joins and enforced schema.
- Impedance mismatch — objects in code vs rows in tables require an ORM translation layer, which can hide performance problems like the N+1 query issue.
- Document model — stores self-contained JSON/BSON blobs; great for one-to-many (embed children); poor at many-to-many (requires application-level joins).
- Schema-on-read ≠ schemaless — the schema exists implicitly in application code; like dynamic type checking vs static type checking.
- Graph model — vertices + labeled directed edges + property maps; no schema restriction on which vertices can connect. Best when relationships are the data.
- Declarative wins — SQL/Cypher let the optimizer decide the execution plan, enabling transparent performance improvements without changing queries.
Relational wins for many-to-many joins and strong schema guarantees. Document wins for self-contained hierarchical data and schema flexibility. Graph wins when relationships are the data. Know the tradeoffs; most production systems mix all three.
Original Notes
The handwritten study notes this chapter summary is based on:
Relational Model vs Document Model
Edgar Codd proposed the relational model in 1970: data is organized into relations (tables), each a collection of tuples (rows). The relational model's key insight was that application code should not need to know the physical storage layout — the database engine handles it, exposing a clean declarative query interface. For decades this dominated every serious data system, and SQL remains the lingua franca of data engineering to this day.
NoSQL emerged prominently in the 2010s, driven by several distinct motivations: the need for greater write scalability than a single SQL database could provide; schema flexibility for rapidly evolving data models in fast-moving startups; a better impedance match for certain data structures that are awkward to express in tables; and the desire for geographically distributed, highly available systems where strict relational consistency was a bottleneck. "NoSQL" is a broad umbrella covering document stores, key-value stores, wide-column stores, and graph databases — they share only the property of not using the relational model, and their tradeoffs differ dramatically from each other.
The Résumé Example: Why Documents Feel Natural
Kleppmann uses a LinkedIn-style résumé (user profile) as a running example, and it is worth unpacking in detail because it cleanly illustrates when each model wins. A résumé has a hierarchical structure: one user identity, but potentially many positions (each with company, title, start date, end date), many education entries, many skills, many contact methods. This is a classic one-to-many structure radiating from a single root entity.
In a relational database you model this as separate tables: users, positions, education, skills. Each child table has a foreign key back to the user. Reading a complete profile requires a JOIN across all these tables — or multiple sequential queries. Writing a new profile requires inserting rows into multiple tables, ideally within a transaction. The data is normalized: the user's name appears in exactly one place.
In a document database (MongoDB, CouchDB, DynamoDB's document mode) you store the entire profile as one JSON document. Positions are an array of sub-objects embedded directly in the user document. Reading a complete profile is one document fetch — no JOIN needed. The data locality is natural. The entire profile is self-contained.
For this specific use case — read one complete profile, write one complete profile — the document model wins on simplicity and read performance. The relational model's normalization benefits (eliminating redundancy, enabling flexible queries across all profiles) matter less when the dominant access pattern is "fetch this user's complete profile."
Object-Relational Impedance Mismatch
Most application code today is written in object-oriented or functional languages. The natural unit of data in application code is an object or a struct with nested fields. The natural unit of data in a relational database is a row in a flat table. The translation between these two representations — typically handled by ORM frameworks like Hibernate (Java), ActiveRecord (Ruby), SQLAlchemy (Python), or Prisma (TypeScript) — is the impedance mismatch.
The impedance mismatch is not merely an inconvenience. It introduces several classes of real problems:
- The N+1 query problem: An ORM fetches N parent records, then lazily executes N separate queries to fetch each parent's children — a total of N+1 database roundtrips where a single JOIN would have done it in one. ORMs can mitigate this with eager loading, but developers must know to configure it, and it is easy to miss in code review.
- Dual mental models: Developers must simultaneously maintain a mental model of the object graph in code and the relational schema in the database. These inevitably diverge subtly over time as one is updated without the other.
- Schema migration coupling: Adding a field to an application object requires a database schema migration (ALTER TABLE), which can lock tables, require deployment coordination, and break backward compatibility with old application instances still running during a rolling deploy.
- ORM-generated query quality: ORMs can generate surprisingly inefficient SQL — Cartesian products, redundant subqueries, or missing indexes — that is invisible to the developer until a query becomes slow in production.
The N+1 query problem is the single most common ORM-related performance issue in production systems. If you have a list of orders and want to display each order's customer name, a naive ORM fetch of 100 orders might issue 101 database queries (1 for orders + 100 for customers) instead of 1 query with a JOIN. Always check ORM-generated SQL in development and configure eager loading explicitly for known access patterns.
One-to-Many, Many-to-One, and Many-to-Many
The relationship structure of your data is the most reliable guide to which data model to choose. Kleppmann breaks relationships into three categories, and the tradeoffs differ for each.
One-to-many relationships (a user has many positions; a blog post has many comments; an order has many line items) are the document model's strong suit. The "many" side can be embedded as an array inside the parent document. Reads are locality-friendly; the entire hierarchy is in one place. Document databases shine here. The relational model can handle this via child tables with foreign keys, but it requires a JOIN that the document model avoids.
Many-to-one relationships (many users live in the same city; many products belong to the same category; many employees work at the same company) favor normalization in a relational database. You store the city as a row in a cities table, referenced by ID. This eliminates redundancy: if a city's name changes, you update one row, not thousands of user records. It also enables referential integrity: you cannot insert a user whose city_id does not exist.
Document databases have weak or no support for enforcing many-to-one referential integrity. Joins are either application-level (fetch the user, then fetch the city by ID in a second query) or not supported at all. This is the core weakness of the document model: it handles the "embed children" case well but handles "reference shared data" poorly. In practice this means document databases encourage denormalization — storing the city name directly in the user document — which creates update anomalies: if the city's name changes, you must find and update every user document that contains it.
Many-to-many relationships (a book has many authors; an author has many books; a tag applies to many posts; a post has many tags) are where the document model struggles most. You cannot simply embed: you cannot embed all of an author's books inside each tag document and also embed all tags inside each author document without massive redundancy. The relational model handles this cleanly with a join table (book_authors with book_id and author_id). Graph databases are even more natural for highly connected many-to-many data.
This historical arc is worth understanding. Early network model databases (IMS, CODASYL) in the 1960s and 1970s modeled data as a record tree with links between records. Many-to-many relationships were navigated manually by following pointers — what CODASYL called "access paths." A query was essentially a program: traverse this link, then that link, then find the matching record. This was powerful but required developers to know the physical layout of data and write navigation code explicitly. Adding a new access path often required rewriting queries. The relational model's revolutionary contribution was eliminating manual path navigation — the query optimizer chooses the access path, freeing the developer to think only about what data they want, not how to fetch it.
Normalization: Why It Matters
Normalization is the process of structuring a relational database to reduce data redundancy and improve data integrity. The key idea: each fact appears in exactly one place. If a city name is stored in a cities table and referenced by ID everywhere else, changing the city's name requires one update. If the city name is stored redundantly in every user record, a name change requires a bulk update across potentially millions of rows — and if any row misses the update, the data becomes inconsistent.
Normalization trades redundancy for join complexity. Normalized databases are smaller, more consistent, and easier to update correctly; but reading denormalized views of the data requires joins, which are more expensive than simple lookups. This is the fundamental tension the relational model manages through its query optimizer and indexing machinery. Document databases lean toward denormalization (embed the data, avoid joins), accepting redundancy in exchange for faster reads and simpler queries for the dominant access pattern.
In practice, "fully normalized" and "fully denormalized" are two ends of a spectrum. Production systems are often somewhere in the middle — highly normalized for frequently updated reference data, selectively denormalized for frequently read, rarely updated aggregates. The rise of materialized views, read replicas, and caching layers can be seen as managed denormalization — keeping normalized data as the source of truth while serving denormalized views for read performance.
Schema-on-Read vs Schema-on-Write
| Property | Schema-on-Write (Relational) | Schema-on-Read (Document) |
|---|---|---|
| Schema enforcement | At write time by the DB; invalid data is rejected | At read time by application code; DB accepts anything |
| Adding a new field | ALTER TABLE migration (may lock table, requires coordination) | Just start writing new documents; old ones return null/missing field |
| Heterogeneous data | Hard — every row must conform to the schema | Easy — different documents in the same collection can have different fields |
| Data integrity | Guaranteed by DB constraints (NOT NULL, FOREIGN KEY, CHECK) | Application's responsibility — bad data can be written and only fail at read time |
| Query flexibility | Strong — optimizer handles multi-table joins and arbitrary filtering | Weaker — poor multi-document join support; cross-collection queries require application logic |
| Schema evolution | Explicit, versioned, can be atomic — but migrations are operational risk | Implicit, gradual, backward-compatible by default — but no enforcement |
Schema-on-read is sometimes called "schemaless," but Kleppmann rightly points out that this is misleading — the schema is not absent, it is merely implicit in application code. Every line of code that reads a field from a document embeds an assumption about what fields exist and what types they have. If that assumption is violated (because old documents have a different structure than new ones), the application breaks at runtime rather than at write time. The analogy Kleppmann uses is precise: schema-on-write is like static (compile-time) type checking — errors are caught early, before the data reaches storage. Schema-on-read is like dynamic (runtime) type checking — errors surface only when the problematic data is accessed.
Neither approach is universally superior. Schema-on-write is better when data integrity is paramount, when the schema is stable, and when queries span many heterogeneous records. Schema-on-read is better when each item's structure is genuinely variable (different types of events in a log, products with different attribute sets), when schema evolution needs to happen quickly without coordinated migrations, or when data comes from external systems over which you have no control.
Data Locality and When It Matters
Document databases often store a document as a single contiguous encoded blob (JSON in MongoDB, BSON in Couchbase, a binary encoding in DynamoDB). If your application frequently needs the entire document — the whole user profile, the whole order with all its line items — this data locality is a genuine performance advantage: a single disk read fetches everything you need, rather than multiple reads across tables joined by foreign keys.
The locality advantage disappears — or even reverses — in several situations. If you typically only need a small subset of a document's fields, you still load the entire blob, wasting I/O. If a document grows very large (embedded arrays with hundreds of entries), random access into the middle becomes expensive. If documents are updated in ways that increase their size, many document databases must rewrite the entire document to a new location on disk, making updates more expensive than in-place row updates. Locality therefore helps most for documents that are read as a whole, written rarely as a whole, and relatively bounded in size.
Kleppmann also notes that relational databases have their own locality mechanisms. Google's Spanner allows declaring a table as interleaved within another (physically co-located on disk). Oracle's multi-table clusters store related rows from different tables in the same disk block. Column-family databases like Cassandra and HBase allow grouping columns that are frequently accessed together into the same storage unit. Locality is a spectrum, not a binary feature of document vs relational systems.
Query Languages: Declarative vs Imperative
The query language a model pairs with is as important as the model itself, because it determines what can be expressed efficiently and what optimization opportunities the engine has. Kleppmann draws a sharp distinction between declarative and imperative approaches.
Declarative Query Languages: SQL
SQL is declarative: you describe what data you want, not the steps the database should take to retrieve it. SELECT * FROM users WHERE city_id = 42 ORDER BY last_name says nothing about whether to use an index, which join algorithm to apply, or whether to parallelize execution. Those decisions belong to the query optimizer. This separation between what (the query) and how (the execution plan) is architecturally profound.
Because the query is a specification rather than a program, the database engine can rewrite it freely. An optimizer can choose between a sequential scan and an index scan based on table statistics. It can reorder joins, push down filters, and apply transformations that a human developer would never write manually. When PostgreSQL improves its query optimizer in a new version, all existing queries automatically benefit — no application code changes needed. This transparency is one of the most underappreciated properties of declarative query languages.
CSS selectors and XPath are also declarative, and Kleppmann uses them as illustrative analogies. When you write li.selected > p { color: green; }, you are specifying a rule about which elements to style, not a traversal algorithm. The browser's CSS engine handles the matching. If the engine is optimized, your styles render faster without any change to your CSS.
MapReduce: Between Declarative and Imperative
MapReduce is a programming model (not a query language) for processing large datasets in parallel across many machines, popularized by Google's 2004 paper and implemented in Hadoop. The developer writes two functions: a map function that transforms each input record into key-value pairs, and a reduce function that aggregates all values for each key. The framework handles parallelization, shuffling, and fault tolerance.
MapReduce is neither purely declarative nor purely imperative. The map and reduce functions are written in a general-purpose language (Java, Python, Go), which gives full expressive power — you can express any transformation you can write code for. The cost is that the framework cannot optimize the execution beyond what you explicitly code. There is no query optimizer rewriting your map function for efficiency. MongoDB initially used JavaScript-based MapReduce for complex aggregations; it later added an aggregation pipeline (a more declarative, composable sequence of stages) that the engine can optimize better and that most developers find easier to use.
-- Declarative SQL: optimizer picks the execution plan
SELECT region, COUNT(*) AS cnt
FROM observations
WHERE animal_family = 'Sharks'
AND date_part('year', observation_date) = 2023
GROUP BY region;
-- MapReduce equivalent (pseudocode): developer controls execution
map(record):
if record.family == 'Sharks' and record.year == 2023:
emit(record.region, 1)
reduce(region, counts):
emit(region, sum(counts))The SQL version is shorter, more readable, and benefits from the optimizer's ability to apply statistical knowledge. The MapReduce version is more flexible — you could add arbitrarily complex logic in the map function — but it is the developer's job to make it correct and efficient. For most analytical aggregations, the SQL approach is superior. MapReduce's value was in the era before SQL-capable systems could operate at the scale of Hadoop clusters; today most large-scale analytics uses SQL-on-Hadoop engines (Hive, Presto, Spark SQL) that compile SQL into distributed execution plans.
Graph Data Model
When many-to-many relationships are not just present but pervasive — when the relationships between entities are as interesting as the entities themselves — neither the relational nor the document model is particularly natural. Relational databases can model graphs (vertices as rows in one table, edges as rows in another), but graph traversal queries (find all paths between two nodes, count common friends, identify communities) become cumbersome recursive SQL. Document databases model graphs even more awkwardly. Graph databases (Neo4j, Amazon Neptune, JanusGraph, TigerGraph) provide a model and query language designed specifically for this access pattern.
Property Graphs
The property graph model — used by Neo4j and most popular graph databases — consists of:
- Vertices (also called nodes): entities like people, places, events. Each vertex has a unique ID, a set of labels (e.g. "Person", "Location"), and a map of properties (key-value pairs).
- Edges (also called relationships): directed connections between vertices. Each edge has a unique ID, a label (e.g. BORN_IN, LIVES_IN, MARRIED_TO), a tail vertex (start), a head vertex (end), and its own map of properties.
Crucially, there is no schema restriction on which vertices can connect to which. A BORN_IN edge can connect a Person vertex to a City vertex, or a Country vertex, or any other vertex. This flexibility makes it easy to extend the data model: adding a new relationship type does not require any schema change. The data model grows organically as new relationship types are discovered.
Two important implementation notes: any vertex can be found efficiently by both its outgoing and incoming edges (the graph is navigable in both directions). Vertices and edges can each carry arbitrary key-value properties, so you can attach metadata to the relationship itself (e.g. a MARRIED_TO edge could have a since property for the year of marriage).
Cypher Query Language
Cypher is Neo4j's declarative graph query language. It uses a visual ASCII-art pattern syntax to describe graph structures, which makes it remarkably readable even for moderately complex queries. The pattern (person)-[:BORN_IN]->(city)-[:WITHIN*0..]->(country {name: 'United States'}) should be read as: "find a person vertex connected via a BORN_IN edge to a city vertex, connected via any number of WITHIN edges to a country vertex named United States." The *0.. means "traverse zero or more WITHIN edges" — a variable-length path that recurses up a location hierarchy (city → state → country).
-- Find people born in the USA who now live in Europe
MATCH
(person)-[:BORN_IN]->()-[:WITHIN*0..]->(usa:Location {name:'United States'}),
(person)-[:LIVES_IN]->()-[:WITHIN*0..]->(eu:Location {name:'Europe'})
RETURN person.name
-- Equivalent SQL requires recursive CTEs and is far more verbose
WITH RECURSIVE within_usa(vertex_id) AS (
SELECT vertex_id FROM vertices WHERE properties ->> 'name' = 'United States'
UNION
SELECT e.tail_vertex FROM edges e, within_usa w
WHERE e.head_vertex = w.vertex_id AND e.label = 'within'
)
-- ... and then further joins for born_in and lives_inThe Cypher version is not just shorter — it is structurally closer to how you think about the question ("find people born in the US who live in Europe") than the SQL version, which requires explicit recursion and manual join construction. For queries involving variable-length paths and graph traversal, Cypher (and similar graph query languages) are genuinely more expressive than SQL without WITH RECURSIVE.
Triple-Stores and SPARQL
A triple-store models all data as (subject, predicate, object) triples. For example: (Jim, likes, bananas), (Jim, bornIn, Berlin), (Berlin, type, City). When the object is another resource (not a literal string or number), the triple encodes an edge in a graph: (Jim, bornIn, Berlin) is an edge from the Jim vertex to the Berlin vertex with label "bornIn." This means every property graph can be expressed as a set of triples — the models are equivalent in expressive power, they differ in syntax and ecosystem.
RDF (Resource Description Framework), developed by the W3C, is the most widely used triple-store format. Subjects and predicates are URIs (globally unique identifiers), which makes RDF data combinable across sources — you can merge RDF datasets from different organizations without renaming conflicts. SPARQL (SPARQL Protocol and RDF Query Language) is the declarative query language for RDF triple-stores. It has a pattern-matching syntax similar in spirit to Cypher.
Datalog is an older precursor to SPARQL, based on Prolog's logic programming approach. It defines rules: if these facts hold, then conclude this derived fact. Datalog is the foundation of Datomic (Rich Hickey's immutable database) and appears in academic research on deductive databases. It is more general than SPARQL — you can express recursive and complex derived facts — but also harder to read for developers not familiar with logic programming. Kleppmann includes it to show the full breadth of declarative query models.
| Model | Best Fit | Query Language | Example Systems |
|---|---|---|---|
| Relational | Structured tabular data; many-to-many with joins; enforced schema; financial/transactional data | SQL | PostgreSQL, MySQL, Oracle, SQL Server |
| Document | Self-contained hierarchical records; schema flexibility; one-to-many embedded relationships; heterogeneous item types | MongoDB query API, DynamoDB expressions | MongoDB, CouchDB, DynamoDB, Firestore |
| Property graph | Highly connected data; variable-length path queries; social networks, knowledge graphs, recommendation engines | Cypher, Gremlin | Neo4j, Amazon Neptune, JanusGraph |
| Triple-store | Semantic data; globally federated datasets; knowledge engineering; ontologies | SPARQL, Datalog | Datomic, Apache Jena, Amazon Neptune (RDF) |
Why Data Models Matter More Than You Think
Kleppmann opens the chapter with an observation worth pausing on: "Data models are perhaps the most important part of developing software, because they have such a profound effect: not only on how the software is written, but also on how we think about the problem that we are solving." This is not hyperbole. A data model shapes not just the database schema but the entire vocabulary of the system — what concepts exist, how they relate, what operations are natural and what are awkward.
Choosing the relational model for a social network graph means that "find my second-degree connections" becomes a recursive SQL query — possible but unnatural. Choosing a graph model means it becomes a one-line Cypher pattern — the structure of the query mirrors the structure of the problem. The data model determines what is easy and what is hard, and that shapes what features get built and what gets deferred as "too complex." Engineers who only know one data model will try to fit every problem into it, often producing systems that are harder to build, harder to understand, and harder to scale than they need to be.
No single data model wins universally. The choice should be driven by the relationship structure of your data and the dominant access patterns. Self-contained hierarchical records with one-to-many children → document model. Structured data with complex many-to-many joins and schema enforcement → relational. Highly connected data where relationships are first-class and path queries are common → graph. When in doubt in an interview: start with relational (it is the most familiar and versatile), then justify any divergence by pointing to a specific structural property of the data — not just "NoSQL scales better" (that is almost always wrong as stated).
When would you choose a document DB over a relational DB? When data is genuinely self-contained hierarchical records (a user profile with embedded positions, a product with embedded variants), you rarely need cross-document joins, and schema fields evolve frequently enough that ALTER TABLE migrations are operationally painful. Do not choose document just for "scale" — relational databases scale very well with read replicas and partitioning.
What is the impedance mismatch? The translation gap between in-memory objects (classes/structs in application code) and flat relational rows/tables, bridged by ORMs. The N+1 query problem is the most common performance consequence: fetching N parents triggers N separate child queries instead of one JOIN.
Schema-on-read vs schema-on-write — which is better? Neither universally. Schema-on-write (relational) catches data quality issues early and enables the database to guarantee integrity. Schema-on-read (document) allows heterogeneous documents and faster schema evolution. The analogy is static vs dynamic type checking — different tradeoffs for different contexts.
Why is SQL declarative and why does it matter? You describe what data you want; the query optimizer decides how to retrieve it — which index, which join algorithm, whether to parallelize. This means database version upgrades that improve the optimizer transparently improve all queries, without any application code changes.
When would you use a graph database? When relationship traversal is the dominant query pattern and relationship depth is variable or unbounded — social network friend-of-friend queries, recommendation engines, fraud detection (identifying connected accounts), knowledge graphs. Relational can model graphs but recursive SQL is verbose and often slow; graph databases make traversal queries natural and fast.