酒店预订平台是一个在关键路径上有严格正确性要求的双边市场:双重预订一个房间是严重的用户体验失败,而错误地阻塞可用库存损失收入。核心设计挑战是在全球用户群跨多个日历天的住宿下、在必须挺过网络故障、支付超时和用户放弃的结账流程中,维护准确的房间可用性——全都绝不把同一晚卖给两个不同客人。除了那个正确性挑战,平台还必须跨数十万家酒店服务快速、过滤、地理感知的搜索结果,管理每酒店复杂的取消和退款政策,并近实时给酒店运营者提供业务分析。
- 全程 SQL——酒店/房间目录有界且结构化;预订需要 ACID;量不足以证明 NoSQL 复杂度合理。
- DB 级约束防超卖——room_availability 表上的
CHECK (available_count >= 0);并发递减到 -1 在数据库失败,而非应用层。 - 低争抢用乐观锁——用一个
version列;冲突时重试;用户搜索和预订确认之间不持行级锁。 - Redis TTL 持有(~10 分钟)——结账期间软预留房间;若用户放弃未完成支付,TTL 过期自动释放。
- Kafka → Elasticsearch——酒店/房间创建或更新事件异步喂搜索索引;售罄房间自动从结果移除。
- 幂等预订 API——客户端提供的幂等键防止重试请求(双击、网络重试)的重复预订。
- S3 + CDN 做媒体——酒店图片住在对象存储;CDN 边缘节点以低延迟全球服务它们。
全程用 SQL 以求 ACID 正确性——酒店和房间数据大小有界,且预订需要事务完整性。available_count 上的行级约束在数据库级别防超卖。带 ~10 分钟 TTL 的 Redis 持有桥接结账间隙而不永久阻塞库存。Kafka 把列表变更喂进 Elasticsearch 做搜索。CDN 全球分发酒店媒体。取消和退款是它们自己的幂等状态机路径。
第 1 步 — 澄清需求
画框前界定系统。酒店预订覆盖很广——把它收窄到一个可辩护、连贯的子集。
功能需求(酒店管理)
- 酒店和房间的 CRUD 操作(名、描述、设施、位置、图片)。
- 设房间定价——基础费率、季节费率、最少住宿、折扣规则。
- 管理可用性日历——封锁特定日期、设每晚房间数。
- 查看和管理预订:确认、取消、修改、处理 no-show。
- 访问业务洞察:入住率、收入、预订提前期、取消率。
功能需求(用户)
- 按城市/位置、入住和退房日期、客人数、过滤器(评分、设施、价格区间)搜索酒店。
- 查看酒店详情:照片、房型、设施、可用性日历、评论。
- 预订房间:选日期、客人数、附加项;用支付确认。
- 查看和管理自己的预订:看确认、改日期、取消。
- 在预订确认、提醒和取消时收 email/push 通知。
非功能需求
- 高一致性——无双重预订;可用性计数必须始终正确。
- 低延迟——搜索和酒店详情页 200 ms p99 内;结账须感觉即时。
- 高可用——预订服务宕意味损失收入;目标 99.99%。
- 可扩展——处理全球用户负载和季节性高峰(夏季、假日、大型活动)。
- 持久性——一个已确认预订绝不丢失。
显式划出范围:忠诚度计划、第三方 OTA(在线旅行社)集成、动态房间升级逻辑、欺诈检测。这些是真实产品功能,但 45 分钟吃完整范围会让难的部分——并发控制和预订状态机——没时间。
第 2 步 — 容量估算
酒店预订是读多、写谨慎的系统。假设一个大 OTA(Booking.com / Expedia 规模):全球 50 万家酒店、每天 1M 预订。
流量
- 搜索请求:假设 50M DAU × 5 搜索/天 = 250M 搜索/天 ≈ ~2,900 搜索/秒平均;峰值(周五下午、假日季)5× → ~14,500 搜索/秒。
- 预订写:1M 预订/天 ÷ 86,400 ≈ ~12 预订/秒平均;闪促期间峰值可能 10× → ~120 预订/秒。带恰当索引的 SQL 可管理。
- 读写比 ≈ 250:1——搜索的重缓存必不可少;预订写相对罕见但必须完美正确。
存储
- 酒店:全球 ~50 万家 × 每条 ~5 KB(元数据、坐标、设施标志)≈ ~2.5 GB——很小,轻易装进 SQL 还有余。
- 房间:~3M 房型 × ~2 KB ≈ ~6 GB。
- 可用性表:3M 房型 × 365 天 × 每行 ~20 字节 ≈ ~22 GB/年——仍 SQL 可管理;按日期分区使查询快。
- 预订:1M/天 × ~500 字节 × 365 天 ≈ ~180 GB/年预订记录——单个 SQL 实例舒适;需要时分片。
- 媒体:酒店照片/视频在 S3——为 PB 级规划;不在 DB。
数据量确认 SQL 是正确的主存储——没有规模理由用 NoSQL 复杂度。难问题不是存储而是可用性表上的并发写正确性。
第 3 步 — API 设计
跨酒店管理和面向用户服务的干净 REST 面:
# 酒店管理 — 列表管理
POST /hotels -- 创建酒店
PUT /hotels/{id} -- 更新酒店
GET /hotels/{id} -- 获取酒店详情
PUT /hotels/{id}/rooms/{room_id} -- 更新房间
GET /hotels/{id}/rooms -- 列出酒店房间
PUT /rooms/{room_id}/availability -- 按日期范围设 available_count
# 用户 — 搜索与发现
GET /hotels/search?city=Paris&checkin=2025-07-01&checkout=2025-07-05&guests=2&max_price=200
GET /hotels/{id}/availability?checkin=...&checkout=...
# 用户 — 预订(经 Idempotency-Key 头幂等)
POST /bookings
Idempotency-Key: "client-uuid-123"
{ hotel_id, room_id, checkin, checkout, guests, payment_method_id }
→ 201 { booking_id, status: "RESERVED", hold_expires_at }
GET /bookings/{id} -- 预订状态和详情
DELETE /bookings/{id} -- 取消预订(触发退款)
PUT /bookings/{id}/modify -- 改日期(若酒店政策允许)POST /bookings 端点携带一个 Idempotency-Key 头。用同键重试的请求(双击、网络超时)返回已存在的预订而非创建第二个。这必不可少,因为预订流程涉及一次支付扣款——没有幂等,客户端和服务器间的网络故障能导致给客人卡上扣两次。
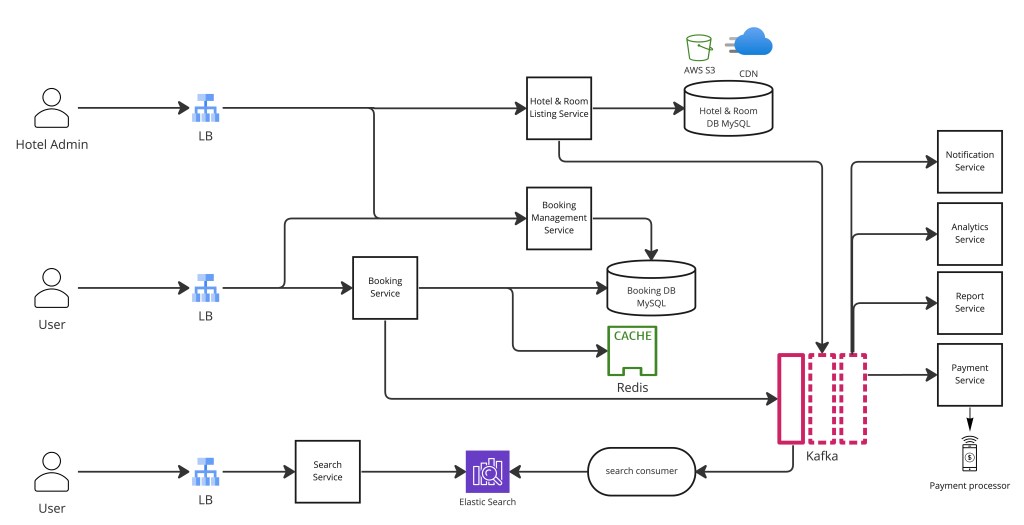
第 4 步 — 酒店和房间列表服务
酒店和房间目录存在一个 SQL 数据库。理由刻意简单:世界上酒店数量有限且可预测地增长。关系数据库是正确契合——数据结构化、增长可预见、查询模式(按 ID 查酒店、按酒店列房间)很适合 SQL 索引。
酒店图片和视频存在 AWS S3(或等价对象存储)。SQL 数据库持有这些媒体资产的引用(URL)。一个 CDN 坐在 S3 前以低延迟服务全球用户群——从地理上邻近的 CDN 边缘节点取酒店图片比命中 us-east-1 的源桶快数个数量级。
酒店或房间被创建或更新时,变更作为事件发布到 Kafka。一个消费者读这些事件并异步更新 Elasticsearch 搜索索引,使搜索结果与真相来源最终一致。售罄房间随 available_count 降到零从结果移除——这个移除流经同一 CDC 管道,而非预订路径上的直接 Elasticsearch 写。
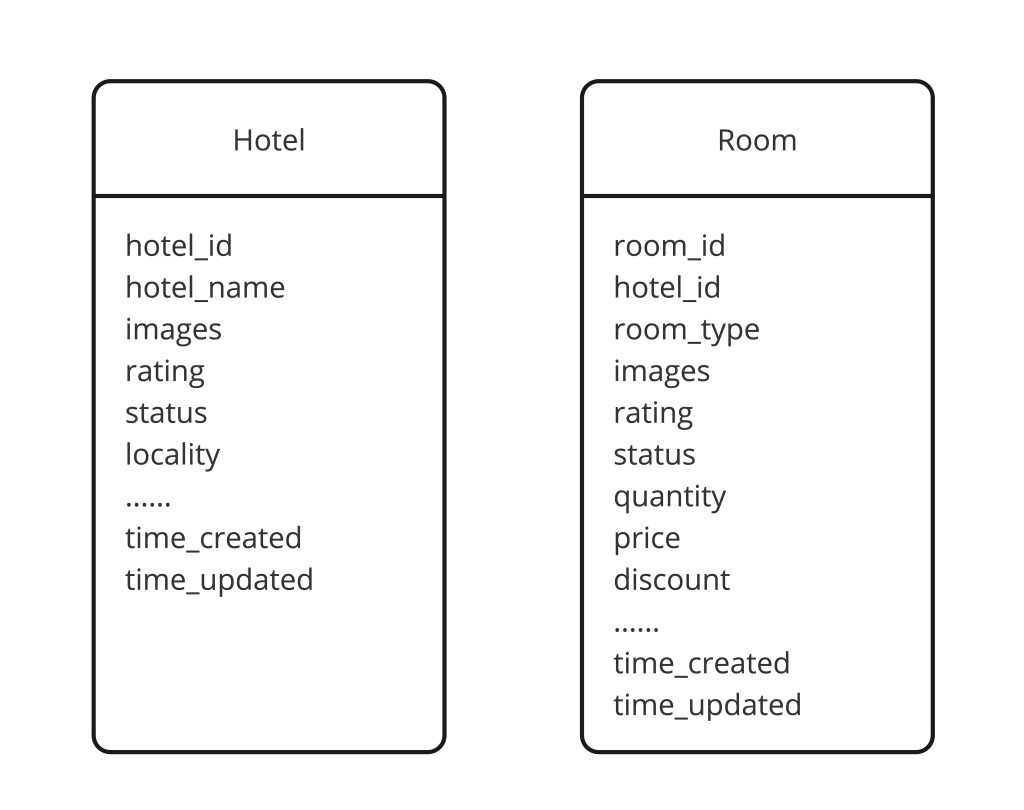
第 5 步 — 数据模型
核心表跨酒店目录和预订系统。全住在 SQL 以求 ACID 正确性:
CREATE TABLE hotels (
id BIGINT PRIMARY KEY,
name VARCHAR(255) NOT NULL,
city VARCHAR(100),
country VARCHAR(2), -- ISO 3166-1 alpha-2
lat DECIMAL(9,6),
lng DECIMAL(9,6),
star_rating SMALLINT,
description TEXT,
amenities JSONB, -- 泳池、wifi、停车、宠物友好...
created_at TIMESTAMP
);
CREATE TABLE rooms (
id BIGINT PRIMARY KEY,
hotel_id BIGINT REFERENCES hotels(id),
room_type VARCHAR(64), -- STANDARD|DELUXE|SUITE
max_guests SMALLINT,
base_rate_cents INT,
description TEXT
);
CREATE TABLE room_availability (
room_id BIGINT REFERENCES rooms(id),
date DATE,
available_count INT NOT NULL CHECK (available_count >= 0),
price_cents INT NOT NULL, -- 这个特定日期的每晚费率
version INT NOT NULL DEFAULT 0, -- 乐观锁
PRIMARY KEY (room_id, date)
);
CREATE TABLE bookings (
id BIGINT PRIMARY KEY,
user_id BIGINT NOT NULL,
room_id BIGINT NOT NULL,
checkin_date DATE NOT NULL,
checkout_date DATE NOT NULL,
guest_count SMALLINT,
total_cents BIGINT NOT NULL,
status VARCHAR(32), -- RESERVED|BOOKED|CANCELLED|COMPLETED
idempotency_key VARCHAR(64) UNIQUE,
payment_intent_id VARCHAR(128),
hold_expires_at TIMESTAMP, -- Redis TTL 镜像到这做恢复
created_at TIMESTAMP,
updated_at TIMESTAMP
);关键 schema 决策:CHECK (available_count >= 0) 约束是防超卖的数据库级守卫。version 列支持乐观并发控制。idempotency_key UNIQUE 约束在 DB 级别防止重复预订。room_availability 上的 price_cents 列捕获预订时的每晚费率——价格在预订后能变,但客人确认的费率锁在预订记录的 total_cents 里。
第 6 步 — 搜索服务
搜索由一个 Elasticsearch 集群驱动(Solr 是可比替代——两者都建在 Apache Lucene 上)。对列表持续更新(价格变化、可用性、新酒店)的酒店平台,Elasticsearch 因其实时索引和内建地理距离查询是更好契合。
| 特性 | Elasticsearch | Solr |
|---|---|---|
| 最适合 | 时序数据、实时索引、地理查询 | 带重缓存的静态数据集 |
| 模糊搜索 | 优秀(Levenshtein 自动机) | 良好 |
| 地理距离过滤 | 原生 geo_point 类型 + 距离过滤 | 经空间模块支持 |
| Type-ahead | 内建 completion suggester | 经 edge n-gram 支持 |
搜索查询流程
一个典型搜索——"巴黎的酒店,2 个成人,7 月 1–5,最高 €200/晚"——执行如下:
- Elasticsearch 查询——按 city = "Paris"(或从"Paris"中心点 geo_distance)、最低星级、设施过滤。返回按相关性分(混合文本匹配、热度、转化率)排序的酒店 ID。
- 可用性过滤——对每个返回的酒店,查
room_availabilitySQL 表以验证至少一个房型对请求范围内每晚有available_count > 0且price_cents <= 200 × 100。过滤掉无合格房间的酒店。 - 价格计算——对合格酒店,跨住宿日期求和每晚
price_cents,应用促销和忠诚折扣,算出显示总价。 - 返回结果——带缩略图、每晚费率、住宿总价、可用性徽章的分页酒店列表。
热门城市+日期组合(如"巴黎 7 月 4 日周末")的搜索结果能在 Redis 缓存配短 TTL(60–120 s)。可用性变化使受影响酒店 ID 的缓存失效。这显著减少高流量搜索查询的 Elasticsearch 和 SQL 负载,而不长时间服务陈旧可用性数据。
第 7 步 — 预订服务与并发控制
预订服务用 SQL 数据库求其 ACID 保证——双重预订不可接受,而 ACID 事务是防止它的干净方式。核心挑战是多晚可用性:5 晚住宿需要 room_availability 里五个独立行 available_count > 0,且所有五个递减必须原子地全成或全败——没有有效的部分预订。
悲观锁
一种方法是用 SELECT ... FOR UPDATE 提前锁住住宿的所有行,然后递减并提交。这安全但在事务期间持锁——包括事务边界内发生的任何外部调用(如支付处理)。等 Stripe API 响应(能花 2–5 秒)时持 DB 锁是负载下连接池耗尽的配方。
乐观锁(首选)
首选方法用 room_availability 上的 version 列做乐观并发控制。用户搜索和预订确认之间不持锁——事务只在实际写的那一刻打开:
-- 第 1 步:读当前状态(无锁)
SELECT date, available_count, version
FROM room_availability
WHERE room_id = 42
AND date BETWEEN '2025-07-01' AND '2025-07-04';
-- → 返回 4 行,version=7,8,7,9,available_count=3,3,2,3
-- 第 2 步:开事务;对每个日期尝试条件递减
BEGIN;
UPDATE room_availability
SET available_count = available_count - 1,
version = version + 1
WHERE room_id = 42
AND date = '2025-07-01'
AND version = 7 -- 乐观锁:若行被修改则失败
AND available_count > 0; -- 防止变负
-- 对住宿所有日期重复
-- 若任何 UPDATE 返回 0 行 → ROLLBACK(有人抢先)
-- 若全成功 → INSERT 预订记录 → COMMIT若 version 检查失败(另一个并发预订修改了其中一行),事务立即回滚,服务用新数据重试。低争抢下(大多数晚),首次尝试成功。高争抢下(热门酒店在高峰周末),服务可能重试 1–3 次再成功或返回"房间不再可用"错误。CHECK (available_count >= 0) 约束是数据库级别的第二道防线——即便应用逻辑有 bug,DB 也拒绝任何低于零的递减。
跨预订和支付服务的两阶段提交会给原子结账——要么都成要么都不成。但 2PC 在整个事务期间跨服务持锁,造成协调者瓶颈并在负载下使可用性暴跌。选的方法(Redis 持有 + 预订上的乐观锁 + 异步支付确认)用严格原子性换高可用,对失败情况带显式补偿动作。
第 8 步 — 结账期间防超卖
用户选房间和完成支付之间,其他用户可能预订同一房间。解法镜像电商购物车模式:一个带 ~10 分钟 TTL 的 Redis 持有在结账期间软预留房间。这创造一个两阶段预订流程:
-- 阶段 1:预留(立即)
用户选房间 + 日期
→ 预订服务: BEGIN TX
对每个住宿日期递减 available_count(乐观锁)
插入 status=RESERVED、hold_expires_at=NOW()+10min 的预订
COMMIT
→ Redis: SET hold:{booking_id} 1 EX 600(镜像 DB 过期)
→ 返回 booking_id + 结账 URL 给用户
-- 阶段 2:确认(10 分钟内)
用户输入支付细节 + 提交
→ 支付服务: 扣卡(Stripe PaymentIntent)
→ webhook: payment.succeeded
→ 预订服务: UPDATE booking SET status=BOOKED
→ 通知: 发确认邮件 + 日历邀请
-- 超时路径(用户放弃)
Redis TTL 过期(10 分钟)
→ 过期监听器 / 后台作业检测 hold:* key 被删
→ 预订服务: UPDATE booking SET status=CANCELLED
为每个住宿日期重新递增 available_count
→ 通知: "你的持有已过期"Redis 持有 TTL 过期路径需要一个可靠机制在用户放弃结账时恢复可用性计数。两种方法:
- Redis 键空间通知——订阅
__keyevent@0__:expired事件;触发一个后台作业在 SQL 里释放持有。这是事件驱动的但要求通知订阅者高可用。 - 定时清扫作业——每分钟跑,查
SELECT id FROM bookings WHERE status='RESERVED' AND hold_expires_at < NOW(),并释放每个过期持有。更简单更可靠;清理略延迟(最多 1 分钟)。

第 9 步 — 预订状态机
一个显式状态机防止非法转换并使预订生命周期可审计。每个状态转换由业务事件驱动且幂等——在同一状态收到同一事件两次是 no-op:
RESERVED ← 房间持有,结账进行中(Redis TTL 活跃)
│ payment.succeeded webhook
▼
BOOKED ← 已确认;房间为客人日期锁定
│ 客人退房 / 住宿日期过去
▼
COMPLETED ← 住宿已发生(终态)
从 RESERVED:
→ HOLD_EXPIRED (TTL 过期无支付;房间释放)
→ PAYMENT_DECLINED (支付失败;房间释放)
→ CANCELLED_BY_USER (用户在支付完成前取消)
从 BOOKED:
→ CANCELLED_BY_USER (取消政策窗口内取消)
→ CANCELLED_BY_HOTEL (酒店因超订/运营问题取消)
→ NO_SHOW (客人未到;收 no-show 费)
所有 CANCELLED_* 状态触发:
→ 为每个住宿日期重新递增 available_count
→ 发起退款(如适用,按酒店政策)
→ 通知客人和酒店管理状态机作为 bookings 表的 status 列持久在 SQL 里,由应用级转换检查守卫。每个转换也发出一个 Kafka 事件,允许下游服务(通知、分析、收入报告)反应而不直接耦合到预订服务。
第 10 步 — 支付处理与幂等
酒店预订的支付处理遵循与电商相同的原则,但有一个关键时间差异:酒店支付常在预订时授权但在入住时捕获(或后付酒店在退房时)。这种授权-捕获分离给酒店资金保证、给客人灵活性——但给支付状态机加复杂度。
支付流程
- 结账期间,为整个住宿金额向支付处理器(Stripe)创建一个 PaymentIntent。这授权卡而不扣它——持有出现在客人卡账单上但无钱移动。
- 入住时(或预付酒店立即),捕获授权的 PaymentIntent。若卡授权已过期(通常 7 天),请求新授权。
- 取消时,按酒店取消政策(入住前 X 天免费取消;部分退款;不退款)释放授权或在已捕获时发退款。
每步幂等
POST /bookings调用携带一个客户端生成的幂等键,存在bookings.idempotency_key UNIQUE列。用同键重试的请求返回已存在的预订。- Stripe PaymentIntent ID 存在
bookings.payment_intent_id——若捕获调用在超时后重试,捕获同一 PaymentIntent,绝不双重扣款。 - 来自 Stripe 的 webhook 事件(
payment_intent.succeeded、payment_intent.payment_failed)驱动预订状态转换。每个 webhook 在处理前按其event_id去重——Stripe 至少一次投递 webhook。
若捕获在支付处理器成功但确认成功的 webhook 丢失会怎样?预订卡在 RESERVED 状态而客人的钱实际被捕获。一个每晚对账作业把 RESERVED 状态的预订记录与处理器的已结算交易比较——若一个 PaymentIntent 在 Stripe 被捕获但预订在我们 DB 是 RESERVED,把预订提升到 BOOKED。这个模式(乐观本地状态 + 对账)对任何支付相关系统必不可少。
第 11 步 — 取消与退款
取消是预订生命周期内它自己的状态机。酒店取消政策差异很大——从"随时免费取消"到"入住前 48 小时内不退款"——预订服务必须在取消时强制这些规则,而非仅在预订时。
取消政策强制
- 每个房型有一个
cancellation_policy属性:FREE_CANCEL_UNTIL_DAYS(如入住前 3 天)、PARTIAL_REFUND_PERCENT(如 50%)、NO_REFUND_WINDOW_HOURS(如 24 h 内不退款)。 - 取消请求(
DELETE /bookings/{id})时,预订服务读酒店政策并基于距入住天数计算退款金额。 - 退款金额传给支付服务,它对原始 PaymentIntent 发一笔该金额的 Stripe 退款。
取消时恢复可用性
预订取消时,必须为被取消住宿的每晚恢复可用性计数。这是预订 Saga 里的补偿动作:
-- 补偿动作:取消时恢复可用性
BEGIN;
UPDATE bookings
SET status = 'CANCELLED_BY_USER', updated_at = NOW()
WHERE id = :booking_id
AND status IN ('RESERVED', 'BOOKED'); -- 幂等:已取消则 no-op
UPDATE room_availability
SET available_count = available_count + 1
WHERE room_id = :room_id
AND date BETWEEN :checkin AND :checkout - INTERVAL '1 day';
COMMIT;
-- 然后:经支付服务发退款(异步)
-- 然后:发布 BookingCancelled 事件到 Kafka第 12 步 — 可用性日历
可用性日历是驱动搜索过滤和房间详情视图("给我看这个房型哪些日期可用")的数据结构。带 (room_id, date) 主键的 room_availability 表是权威来源。对面向用户的日历 UI,一个预计算缓存必不可少:
- 把每房间未来 90 天的可用性作有序集合或紧凑位集(每天一位,90 天 = ~12 字节)缓存在 Redis。查找 O(1)。
- 每当一个房间的可用性变化(预订、取消、酒店管理更新)使其缓存条目失效。
- 酒店详情页取缓存日历——对热门酒店通常是完整缓存命中,因为可用性变化比浏览少。
"巴黎,7 月 1–5"的搜索必须验证至少一个房型在所有四晚(7 月 1、2、3、4)有可用性。一个带 GROUP BY 和 HAVING count = 4 的 room_availability SQL 查询正确工作。为规模化的搜索时性能,预计算每房间的"从日期 X 到日期 Y 可用"范围并用日期范围字段在 Elasticsearch 索引它们。这允许 Elasticsearch 做过滤而无需每个搜索命中都打 SQL DB。
第 13 步 — 分析与报告
分析服务从 Kafka 消费两个事件流:搜索动作(用户搜索什么、点击哪些结果)和预订交易(预订、取消、收入)。这些馈送驱动酒店管理仪表盘和平台级报告:
- 入住率——每房型每周期 已预订晚 ÷ 总可用晚。
- 收入趋势——每酒店每日/周/月收入,按房型细分。
- 预订提前期——(入住日期 − 预订日期)的分布;告诉酒店主客人提前多久预订并指导定价策略。
- 取消率——按取消政策类型分段;识别哪些政策驱动收入留存。
- 搜索到预订漏斗——多少搜索导致酒店详情视图 → 持有 → 确认预订;识别流失点。
分析事件从 Kafka 流入一个数据仓库(ClickHouse 或 Redshift),SQL 聚合在那运行而不碰运营 DB。酒店管理仪表盘查仓库;运营预订服务从不用于分析查询。
第 14 步 — 扩展与容错
酒店预订读主导(搜索远超预订)但写关键(预订写必须正确)。各自的扩展策略不同:
搜索扩展
- Elasticsearch 横向可扩展——加 shard 给更大索引、加副本给更高读吞吐。
- 在 Redis 缓存热门搜索查询(城市 + 日期范围)配 60–120 s TTL。大多数搜索流量高度重复(同样热门城市、同样热门日期)。
- 可用性过滤(Elasticsearch 后的 SQL 查找)是重搜索负载下的瓶颈。用读副本和 Redis 里预计算的可用性缓存缓解。
预订写扩展
- ~12 预订/秒平均(120 峰值),单个 SQL 主库舒适处理负载。乐观锁让事务短——无长持行锁。
- 若写规模成关切:按
hotel_id哈希分片room_availability表。一个酒店的所有可用性写去一个分片;预订无需跨分片 join(一个客人一次预订一个酒店)。 bookings表能按user_id分片,使"我的预订"查询单分片。跨分片只为酒店管理视图(我酒店的所有预订)需要——把那些路由到分析副本。
容错
- Redis 故障——若 Redis 宕,预订服务回退到仅 DB 流程:跳过 Redis 持有,用 DB 级约束 + 乐观锁作唯一守卫。DB 负载略高但功能正确。
- 支付处理器超时——若 Stripe API 在捕获时超时,带指数退避重试(PaymentIntent ID 确保幂等)。把预订对用户呈现为 PENDING 直到确认;每晚对账作业抓住任何缺口。
- Kafka 故障——预订继续;Elasticsearch 略落后(搜索可能显示售罄房间直到 Kafka 恢复、索引追上)。DB 始终是真相来源——Elasticsearch 是下游投影。
- DB 主库故障——自动故障转移到备用副本(如带 Patroni 的 PostgreSQL 或 Amazon RDS Multi-AZ)。故障转移期间短暂只读窗口;新预订排队并在新主库选出时重试。
第 15 步 — 为什么不用 Cassandra 做预订?
不像电商订单历史(高量、追加重、适合 Cassandra 归档),酒店预订量低到一个 SQL 主库能保留完整预订历史而无需专用归档服务。在此数据量,ACID 事务的正确性好处胜过 NoSQL 的可扩展好处。具体地:
- 1M 预订/天 × 365 天 × 500 字节 ≈ 180 GB/年——很好地在 SQL 的甜点内。
- ACID 多行更新(跨多个日期递减可用性 + 在一个事务里插入预订记录)不被 Cassandra 的轻量事务原生支持(LWT 是每分区且受限)。
- Cassandra 的最终一致模型会需要复杂的应用级冲突解决来防止双重预订——正是 SQL 行级约束平凡解决的问题。
第 16 步 — 关键取舍
| 决策 | 选择 | 接受的取舍 |
|---|---|---|
| 主存储 | 全程 SQL | 比 NoSQL 更低横向写规模;由自然低的预订写率缓解 |
| 并发控制 | 乐观锁 | 冲突时需重试;热门房间高争抢下重试率飙升——加指数退避 |
| 搜索索引 | Elasticsearch(最终) | 新预订房间在搜索里可能显示可用数秒直到 Kafka 传播;用短 TTL 可用性缓存补偿 |
| 结账持有 | Redis TTL(~10 分钟) | 即便用户放弃房间也被阻塞 10 分钟;用更短 TTL(5 分钟)和清晰 UI 警告缓解 |
| 支付时机 | 现在授权,入住时捕获 | 远期预订的授权能过期(7 天);需要时必须重新授权 |
| 分析 | Kafka → 数据仓库 | 分析最终一致(分钟到小时滞后);对报告用例可接受 |
酒店预订设计全关于一致性:SQL + 行级约束在数据库级别防双重预订;Redis TTL 持有解决结账间隙而不永久阻塞库存;乐观锁让事务短且高并发;Kafka 异步喂 Elasticsearch 使搜索准确。"为什么不 NoSQL"的答案简单——预订量不足以证明牺牲 ACID 合理,且酒店数有界。预订 API 上的幂等键是正确系统和在网络重试时给客人双重扣款的系统之间的区别。
并发请求下怎么防止双重预订?room_availability 表上的 CHECK (available_count >= 0) 约束使任何会递减到零以下的事务在 DB 级别失败。带 version 列的乐观锁确保同一房间+日期的两个并发预订不能都成功——一个会用新数据重试。
为什么不像电商用 Cassandra 做订单历史那样做预订?酒店预订量低到 SQL 能保留完整历史;ACID 事务干净防双重预订;Cassandra 的最终一致模型会需要复杂的应用级冲突解决。
用户选房间后放弃结账会怎样?Redis TTL(~10 分钟)自动过期,触发一个后台作业(或键空间通知处理器)为每个住宿日期重新递增 available_count——无需手动清理或 cron 作业。
怎么让预订 API 幂等?要求一个客户端生成的 Idempotency-Key 头;把它存在 bookings 表作 UNIQUE 列。用同键重试的请求返回已存在的预订而非创建重复——防止网络重试时双重扣款。
怎么处理预订确认时支付处理器超时?在捕获调用前把 PaymentIntent ID 存进预订记录。用同一 PaymentIntent ID 带指数退避重试捕获(Stripe 去重)。一个每晚对账作业抓住任何 PaymentIntent 已捕获但预订还在 RESERVED 状态的预订——把它们提升到 BOOKED。