A hotel booking platform is a two-sided marketplace with strict correctness requirements on the critical path: double-booking a room is a severe user experience failure, while incorrectly blocking available inventory costs revenue. The core design challenge is maintaining accurate room availability under concurrent bookings across a global user base, across a stay that spans multiple calendar days, with a checkout flow that must survive network failures, payment timeouts, and user abandonment — all without ever selling the same night to two different guests. Beyond that correctness challenge, the platform must serve fast, filtered, geo-aware search results across hundreds of thousands of properties, manage complex cancellation and refund policies per-hotel, and provide business analytics to hotel operators in near real time.
- SQL throughout — hotel/room catalog is bounded and structured; booking demands ACID; volume doesn't justify NoSQL complexity.
- DB-level constraint prevents oversell —
CHECK (available_count >= 0)on the room_availability table; concurrent decrements to -1 fail at the database, not the application layer. - Optimistic locking for low-contention — use a
versioncolumn; retry on conflict; no row-level lock held between the user's search and their booking confirmation. - Redis TTL hold (~10 min) — soft-reserves a room during checkout; auto-releases on TTL expiry if user abandons without completing payment.
- Kafka → Elasticsearch — hotel/room create or update events feed the search index asynchronously; fully-booked rooms are removed from results automatically.
- Idempotent booking API — client-supplied idempotency key prevents duplicate reservations on retried requests (double-tap, network retry).
- S3 + CDN for media — hotel images live in object storage; CDN edge nodes serve them globally with low latency.
Use SQL throughout for ACID correctness — hotel and room data is bounded in size, and bookings demand transaction integrity. A row-level constraint on available_count prevents overselling at the database level. A Redis hold with ~10-minute TTL bridges the checkout gap without permanently blocking inventory. Kafka feeds listing changes into Elasticsearch for search. CDN distributes hotel media globally. Cancellation and refund are their own idempotent state machine paths.
Step 1 — Clarify Requirements
Before drawing boxes, scope the system. Hotel booking covers a lot of ground — narrow it to a defensible, coherent subset.
Functional requirements (Hotel Admin)
- CRUD operations for hotels and rooms (name, description, amenities, location, images).
- Set room pricing — base rate, seasonal rates, minimum stay, discount rules.
- Manage availability calendar — block specific dates, set room count per night.
- View and manage bookings: confirm, cancel, modify, handle no-shows.
- Access business insights: occupancy rate, revenue, booking lead time, cancellation rate.
Functional requirements (User)
- Search hotels by city/location, check-in and check-out dates, guest count, filters (rating, amenities, price range).
- View hotel details: photos, room types, amenities, availability calendar, reviews.
- Reserve a room: select dates, guest count, add-ons; confirm with payment.
- View and manage own bookings: view confirmation, modify dates, cancel.
- Receive email/push notification on booking confirmation, reminder, and cancellation.
Non-functional requirements
- High consistency — no double-bookings; availability counts must be correct at all times.
- Low latency — search and hotel detail pages under 200 ms p99; checkout must feel instant.
- High availability — a down booking service means lost revenue; target 99.99%.
- Scalability — handles global user load and seasonal peaks (summer, holidays, major events).
- Durability — a confirmed booking is never lost.
Explicitly scope out: loyalty programs, third-party OTA (Online Travel Agency) integration, dynamic room upgrade logic, fraud detection. These are real product features but eating the full scope in 45 minutes leaves no time for the hard parts — concurrency control and the booking state machine.
Step 2 — Capacity Estimation
Hotel booking is a read-heavy, write-careful system. Assume a large OTA (Booking.com / Expedia scale): 500M hotels globally, 1M bookings/day.
Traffic
- Search requests: assume 50M DAU × 5 searches/day = 250M searches/day ≈ ~2,900 searches/sec average; peak (Friday afternoon, holiday season) 5× → ~14,500 searches/sec.
- Booking writes: 1M bookings/day ÷ 86,400 ≈ ~12 bookings/sec average; peak could be 10× during flash deals → ~120 bookings/sec. Manageable for SQL with proper indexing.
- Read:write ratio ≈ 250:1 — heavy caching is essential for search; booking writes are comparatively rare but must be perfectly correct.
Storage
- Hotels: ~500K hotels worldwide × ~5 KB per hotel record (metadata, coordinates, amenity flags) ≈ ~2.5 GB — tiny, easily fits in SQL with room to spare.
- Rooms: ~3M room types × ~2 KB ≈ ~6 GB.
- Availability table: 3M room types × 365 days × ~20 bytes per row ≈ ~22 GB/year — still SQL-manageable; partition by date to keep queries fast.
- Bookings: 1M/day × ~500 bytes × 365 days ≈ ~180 GB/year of booking records — comfortable in a single SQL instance; shard if needed.
- Media: hotel photos/videos in S3 — plan for petabytes; not in the DB.
The data volumes confirm that SQL is the right primary store — there is no scale justification for NoSQL complexity. The hard problem is not storage but concurrent write correctness on the availability table.
Step 3 — API Design
Clean REST surface across the hotel admin and user-facing services:
# Hotel admin — listing management
POST /hotels -- create hotel
PUT /hotels/{id} -- update hotel
GET /hotels/{id} -- get hotel details
PUT /hotels/{id}/rooms/{room_id} -- update room
GET /hotels/{id}/rooms -- list rooms for hotel
PUT /rooms/{room_id}/availability -- set available_count per date range
# User — search and discovery
GET /hotels/search?city=Paris&checkin=2025-07-01&checkout=2025-07-05&guests=2&max_price=200
GET /hotels/{id}/availability?checkin=...&checkout=...
# User — booking (idempotent via Idempotency-Key header)
POST /bookings
Idempotency-Key: "client-uuid-123"
{ hotel_id, room_id, checkin, checkout, guests, payment_method_id }
→ 201 { booking_id, status: "RESERVED", hold_expires_at }
GET /bookings/{id} -- booking status and details
DELETE /bookings/{id} -- cancel a booking (triggers refund)
PUT /bookings/{id}/modify -- change dates (if hotel policy allows)The POST /bookings endpoint carries an Idempotency-Key header. A retried request with the same key (double-tap, network timeout) returns the existing booking rather than creating a second one. This is essential because the booking flow involves a payment charge — without idempotency, a network glitch between the client and server can result in two charges to the guest's card.
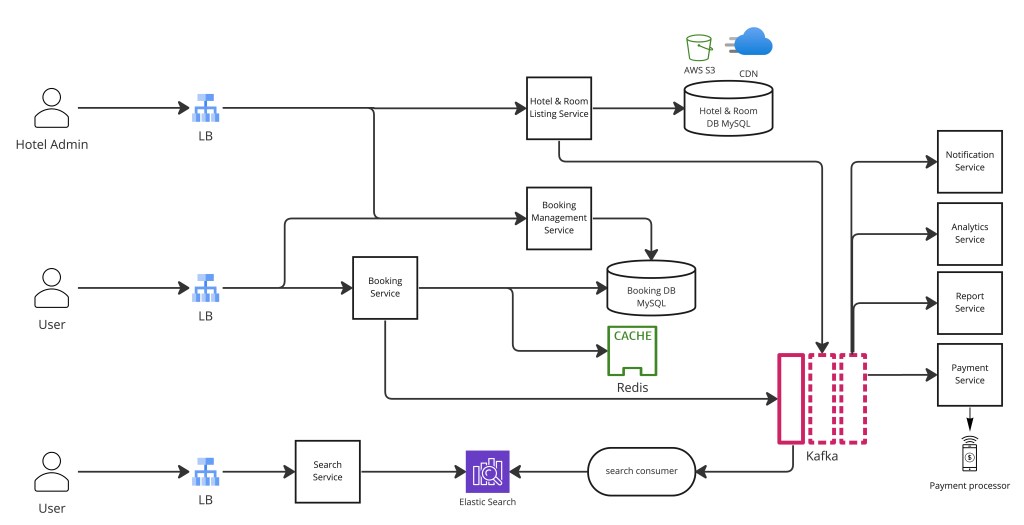
Step 4 — Hotel and Room Listing Service
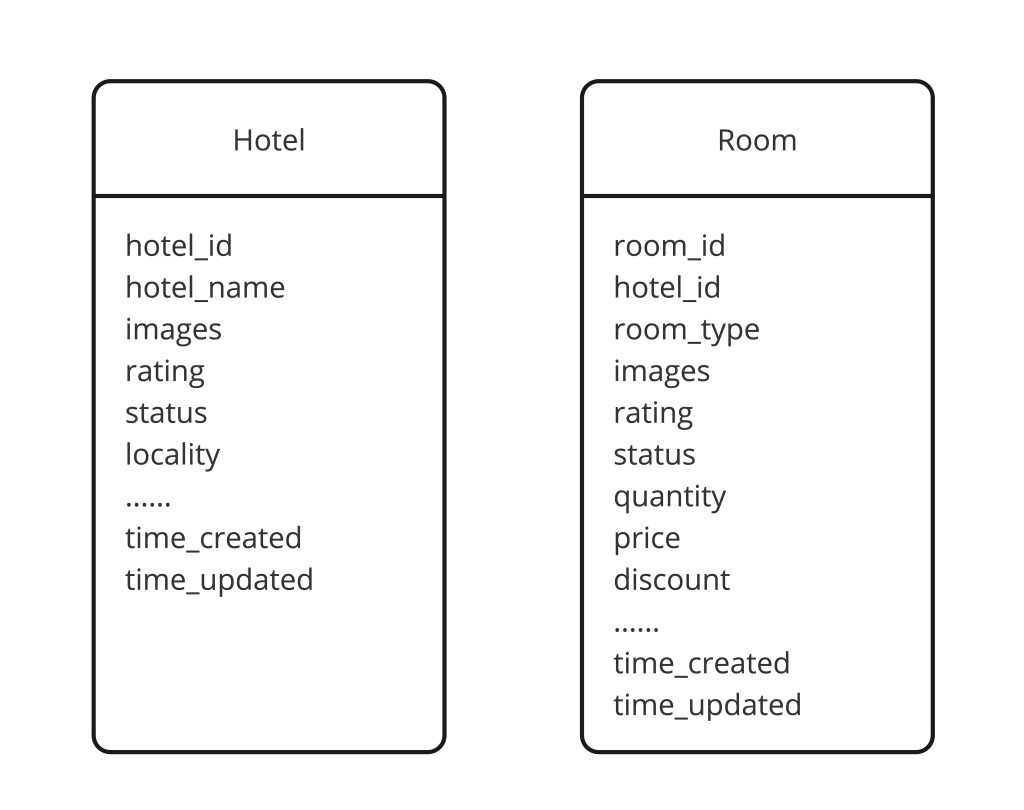
The hotel and room catalog is stored in a SQL database. The rationale is deliberately simple: the number of hotels in the world is finite and grows predictably. A relational database is the right fit — the data is structured, growth is foreseeable, and the query patterns (look up hotel by ID, list rooms by hotel) are well-suited to SQL indexes.
Hotel images and videos are stored in AWS S3 (or equivalent object storage). The SQL database holds references (URLs) to these media assets. A CDN sits in front of S3 to serve media to a global user base with low latency — fetching a hotel image from a geographically proximate CDN edge node is orders of magnitude faster than hitting the origin bucket in us-east-1.
When hotels or rooms are created or updated, the changes are published to Kafka as events. A consumer reads these events and updates the Elasticsearch search index asynchronously, keeping search results eventually consistent with the source of truth. Fully-booked rooms are removed from results as their available_count drops to zero — this removal flows through the same CDC pipeline, not through a direct Elasticsearch write on the booking path.
Step 5 — Data Model
The core tables span the hotel catalog and the booking system. All live in SQL for ACID correctness:
CREATE TABLE hotels (
id BIGINT PRIMARY KEY,
name VARCHAR(255) NOT NULL,
city VARCHAR(100),
country VARCHAR(2), -- ISO 3166-1 alpha-2
lat DECIMAL(9,6),
lng DECIMAL(9,6),
star_rating SMALLINT,
description TEXT,
amenities JSONB, -- pool, wifi, parking, pet-friendly...
created_at TIMESTAMP
);
CREATE TABLE rooms (
id BIGINT PRIMARY KEY,
hotel_id BIGINT REFERENCES hotels(id),
room_type VARCHAR(64), -- STANDARD|DELUXE|SUITE
max_guests SMALLINT,
base_rate_cents INT,
description TEXT
);
CREATE TABLE room_availability (
room_id BIGINT REFERENCES rooms(id),
date DATE,
available_count INT NOT NULL CHECK (available_count >= 0),
price_cents INT NOT NULL, -- per-night rate for this specific date
version INT NOT NULL DEFAULT 0, -- optimistic lock
PRIMARY KEY (room_id, date)
);
CREATE TABLE bookings (
id BIGINT PRIMARY KEY,
user_id BIGINT NOT NULL,
room_id BIGINT NOT NULL,
checkin_date DATE NOT NULL,
checkout_date DATE NOT NULL,
guest_count SMALLINT,
total_cents BIGINT NOT NULL,
status VARCHAR(32), -- RESERVED|BOOKED|CANCELLED|COMPLETED
idempotency_key VARCHAR(64) UNIQUE,
payment_intent_id VARCHAR(128),
hold_expires_at TIMESTAMP, -- Redis TTL mirrored here for recovery
created_at TIMESTAMP,
updated_at TIMESTAMP
);Key schema decisions: the CHECK (available_count >= 0) constraint is the database-level guard against overselling. The version column enables optimistic concurrency control. The idempotency_key UNIQUE constraint prevents duplicate bookings at the DB level. The price_cents column on room_availability captures the per-night rate at booking time — the price can change after booking but the guest's confirmed rate is locked in the booking record's total_cents.
Step 6 — Search Service
Search is powered by an Elasticsearch cluster (Solr is a comparable alternative — both are built on Apache Lucene). For a hotel platform where listings update continuously (price changes, availability, new properties), Elasticsearch is the better fit due to its real-time indexing and built-in geo-distance queries.
| Feature | Elasticsearch | Solr |
|---|---|---|
| Best for | Time-series data, real-time indexing, geo queries | Static data sets with heavy caching |
| Fuzzy search | Excellent (Levenshtein automata) | Good |
| Geo-distance filter | Native geo_point type + distance filter | Supported via spatial module |
| Type-ahead | Built-in completion suggester | Supported via edge n-gram |
Search query flow
A typical search — "hotels in Paris, 2 adults, July 1–5, max €200/night" — executes as follows:
- Elasticsearch query — filter by city = "Paris" (or geo_distance from "Paris" centroid), min star rating, amenities. Return hotel IDs sorted by relevance score (blending text match, popularity, conversion rate).
- Availability filter — for each returned hotel, query the
room_availabilitySQL table to verify at least one room type hasavailable_count > 0for every night in the requested range andprice_cents <= 200 × 100. Filter out hotels with no qualifying rooms. - Price computation — for qualifying hotels, sum the per-night
price_centsacross the stay dates, apply promotions and loyalty discounts, compute the total displayed price. - Return results — paginated list of hotels with thumbnail, nightly rate, total stay price, availability badge.
Search results for popular city+date combinations (e.g., "Paris July 4th weekend") can be cached in Redis with a short TTL (60–120 s). Availability changes invalidate the cache for affected hotel IDs. This significantly reduces Elasticsearch and SQL load for high-traffic search queries without serving stale availability data for long.
Step 7 — Booking Service and Concurrency Control
The booking service uses a SQL database for its ACID guarantees — a double-booking is unacceptable, and ACID transactions are the clean way to prevent it. The central challenge is multi-night availability: a 5-night stay requires available_count > 0 on five separate rows in room_availability, and all five decrements must succeed atomically or all fail — there is no valid partial booking.
Pessimistic locking
One approach is to lock all rows for the stay upfront using SELECT ... FOR UPDATE, then decrement and commit. This is safe but holds locks for the duration of the transaction — including any external calls (e.g., payment processing) that happen inside the transaction boundary. Holding DB locks while waiting for a Stripe API response (which can take 2–5 seconds) is a recipe for connection pool exhaustion under load.
Optimistic locking (preferred)
The preferred approach uses the version column on room_availability for optimistic concurrency control. No locks are held between the user's search and their booking confirmation — the transaction is only opened at the moment of the actual write:
-- Step 1: Read current state (no lock)
SELECT date, available_count, version
FROM room_availability
WHERE room_id = 42
AND date BETWEEN '2025-07-01' AND '2025-07-04';
-- → returns 4 rows with version=7,8,7,9 and available_count=3,3,2,3
-- Step 2: Begin transaction; attempt conditional decrement on each date
BEGIN;
UPDATE room_availability
SET available_count = available_count - 1,
version = version + 1
WHERE room_id = 42
AND date = '2025-07-01'
AND version = 7 -- optimistic lock: fails if row was modified
AND available_count > 0; -- prevents going negative
-- Repeat for all dates in stay
-- If any UPDATE returns 0 rows affected → ROLLBACK (someone beat us to it)
-- If all succeed → INSERT booking record → COMMITIf the version check fails (another concurrent booking modified one of the rows), the transaction rolls back immediately and the service retries with fresh data. Under low contention (most nights), the first attempt succeeds. Under high contention (popular hotel on peak weekend), the service may retry 1–3 times before succeeding or returning a "room no longer available" error. The CHECK (available_count >= 0) constraint is a second line of defense at the database level — even if application logic has a bug, the DB rejects any decrement below zero.
Two-phase commit across booking and payment services would give atomic checkout — either both succeed or neither does. But 2PC holds locks across services for the full transaction duration, creating a coordinator bottleneck and cratering availability under load. The chosen approach (Redis hold + optimistic lock on booking + async payment confirmation) trades strict atomicity for high availability, with explicit compensating actions for the failure cases.
Step 8 — Preventing Overselling During Checkout
Between when a user selects a room and when they complete payment, other users might book the same room. The solution mirrors the e-commerce cart pattern: a Redis hold with a ~10-minute TTL soft-reserves the room during checkout. This creates a two-phase booking flow:
-- Phase 1: Reserve (immediate)
User selects room + dates
→ Booking Service: BEGIN TX
Decrement available_count for each stay date (optimistic lock)
Insert booking with status=RESERVED, hold_expires_at=NOW()+10min
COMMIT
→ Redis: SET hold:{booking_id} 1 EX 600 (mirrors the DB expiry)
→ Return booking_id + checkout URL to user
-- Phase 2: Confirm (within 10 min)
User enters payment details + submits
→ Payment Service: charge card (Stripe PaymentIntent)
→ webhook: payment.succeeded
→ Booking Service: UPDATE booking SET status=BOOKED
→ Notification: send confirmation email + calendar invite
-- Timeout path (user abandons)
Redis TTL expires (10 min)
→ Expiry listener / background job detects hold:* key deleted
→ Booking Service: UPDATE booking SET status=CANCELLED
Re-increment available_count for each stay date
→ Notification: "your hold has expired"The Redis hold TTL expiry path requires a reliable mechanism to restore the availability count when a user abandons checkout. Two approaches:
- Redis keyspace notifications — subscribe to
__keyevent@0__:expiredevents; trigger a background job to release the hold in SQL. This is event-driven but requires the notification subscriber to be highly available. - Scheduled sweeper job — runs every minute, queries
SELECT id FROM bookings WHERE status='RESERVED' AND hold_expires_at < NOW(), and releases each expired hold. Simpler and more reliable; slightly delayed cleanup (up to 1 minute).

Step 9 — Booking State Machine
An explicit state machine prevents illegal transitions and makes the booking lifecycle auditable. Each state transition is driven by a business event and is idempotent — receiving the same event twice in the same state is a no-op:
RESERVED ← room held, checkout in progress (Redis TTL active)
│ payment.succeeded webhook
▼
BOOKED ← confirmed; room locked for guest's dates
│ guest checks out / stay date passes
▼
COMPLETED ← stay has occurred (terminal)
From RESERVED:
→ HOLD_EXPIRED (TTL expired without payment; room released)
→ PAYMENT_DECLINED (payment failed; room released)
→ CANCELLED_BY_USER (user cancelled before payment completed)
From BOOKED:
→ CANCELLED_BY_USER (cancellation within cancellation policy window)
→ CANCELLED_BY_HOTEL (hotel cancels due to overbooking/ops issue)
→ NO_SHOW (guest didn't arrive; charged no-show fee)
All CANCELLED_* states trigger:
→ re-increment available_count for each stay date
→ initiate refund (if applicable, per hotel policy)
→ notify guest and hotel adminThe state machine is persisted in SQL as the status column on the bookings table, guarded by application-level transition checks. Each transition also emits a Kafka event, allowing downstream services (notifications, analytics, revenue reporting) to react without being directly coupled to the booking service.
Step 10 — Payment Processing and Idempotency
Payment processing for hotel bookings follows the same principles as e-commerce but with a critical timing difference: hotel payments are often authorized at booking time but captured at check-in (or at check-out for post-pay hotels). This authorization-capture split gives the hotel a guarantee of funds while giving the guest flexibility — but it adds complexity to the payment state machine.
Payment flow
- During checkout, create a PaymentIntent with the payment processor (Stripe) for the full stay amount. This authorizes the card without charging it — the hold appears on the guest's card statement but no money moves.
- On check-in (or immediately for pre-pay hotels), capture the authorized PaymentIntent. If the card authorization has expired (typically 7 days), request a new authorization.
- On cancellation, release the authorization or issue a refund if already captured, according to the hotel's cancellation policy (free cancellation until X days before check-in; partial refund; no refund).
Idempotency at every step
- The
POST /bookingscall carries a client-generated idempotency key that is stored in thebookings.idempotency_key UNIQUEcolumn. A retried request with the same key returns the existing booking. - The Stripe PaymentIntent ID is stored in
bookings.payment_intent_id— if the capture call is retried after a timeout, the same PaymentIntent is captured, never double-charged. - Webhook events from Stripe (
payment_intent.succeeded,payment_intent.payment_failed) drive booking status transitions. Each webhook is deduplicated by itsevent_idbefore processing — Stripe delivers webhooks at-least-once.
What if the capture succeeds at the payment processor but the webhook confirming success is lost? The booking is stuck in RESERVED state with the guest's money actually captured. A nightly reconciliation job compares booking records in RESERVED state against the processor's settled transactions — if a PaymentIntent is captured in Stripe but the booking is RESERVED in our DB, promote the booking to BOOKED. This pattern (optimistic local state + reconciliation) is essential for any payment-adjacent system.
Step 11 — Cancellation and Refunds
Cancellation is its own state machine within the booking lifecycle. Hotel cancellation policies vary widely — from "free cancellation any time" to "no refund within 48 hours of check-in" — and the booking service must enforce these rules at cancellation time, not just at booking time.
Cancellation policy enforcement
- Each room type has a
cancellation_policyattribute:FREE_CANCEL_UNTIL_DAYS(e.g., 3 days before check-in),PARTIAL_REFUND_PERCENT(e.g., 50%),NO_REFUND_WINDOW_HOURS(e.g., no refund within 24 h). - On cancellation request (
DELETE /bookings/{id}), the booking service reads the hotel's policy and computes the refund amount based on days until check-in. - The refund amount is passed to the Payment Service, which issues a Stripe refund for that amount against the original PaymentIntent.
Availability restoration on cancellation
When a booking is cancelled, the availability count must be restored for each night of the cancelled stay. This is the compensating action in the booking Saga:
-- Compensating action: restore availability on cancellation
BEGIN;
UPDATE bookings
SET status = 'CANCELLED_BY_USER', updated_at = NOW()
WHERE id = :booking_id
AND status IN ('RESERVED', 'BOOKED'); -- idempotent: no-op if already cancelled
UPDATE room_availability
SET available_count = available_count + 1
WHERE room_id = :room_id
AND date BETWEEN :checkin AND :checkout - INTERVAL '1 day';
COMMIT;
-- Then: issue refund via Payment Service (async)
-- Then: publish BookingCancelled event to KafkaStep 12 — Availability Calendar
The availability calendar is the data structure that drives both search filtering and the room detail view ("show me which dates are available for this room type"). The room_availability table with a (room_id, date) primary key is the authoritative source. For the user-facing calendar UI, a pre-computed cache is essential:
- Cache the next 90 days of availability per room in Redis as a sorted set or a compact bitset (one bit per day, 90 days = ~12 bytes). Look up is O(1).
- Invalidate the cache entry for a room whenever its availability changes (booking, cancellation, hotel admin update).
- The hotel detail page fetches the cached calendar — typically a full cache hit since availability changes are less frequent than views for popular hotels.
A search for "Paris, July 1–5" must verify that at least one room type has availability on all four nights (Jul 1, 2, 3, 4). A SQL query on room_availability with a GROUP BY and HAVING count = 4 works correctly. For search-time performance at scale, pre-compute per-room "available from date X to date Y" ranges and index them in Elasticsearch using a date range field. This allows Elasticsearch to do the filtering without hitting the SQL DB on every search hit.
Step 13 — Analytics and Reporting
The Analytics Service consumes two event streams from Kafka: search actions (what users search for, which results they click) and booking transactions (bookings, cancellations, revenue). These feeds power hotel admin dashboards and platform-level reporting:
- Occupancy rates — booked nights ÷ total available nights per room type per period.
- Revenue trends — daily/weekly/monthly revenue per hotel, with breakdown by room type.
- Booking lead time — distribution of (check-in date − booking date); tells hoteliers how far ahead guests book and informs pricing strategy.
- Cancellation rate — segmented by cancellation policy type; identifies which policies drive revenue retention.
- Search-to-book funnel — how many searches result in a hotel detail view → hold → confirmed booking; identifies drop-off points.
Analytics events flow from Kafka into a data warehouse (ClickHouse or Redshift) where SQL aggregations run without touching the operational DB. Hotel admin dashboards query the warehouse; the operational booking service is never used for analytics queries.
Step 14 — Scaling and Fault Tolerance
Hotel booking is read-dominated (searches vastly outnumber bookings) but write-critical (booking writes must be correct). The scaling strategy differs for each:
Search scaling
- Elasticsearch is horizontally scalable — add shards for larger index, add replicas for higher read throughput.
- Cache popular search queries in Redis (city + date range) with a 60–120 s TTL. Most search traffic is highly repetitive (same popular cities, same popular dates).
- The availability filter (SQL lookup after Elasticsearch) is the bottleneck under heavy search load. Mitigate with read replicas and the pre-computed availability cache in Redis.
Booking write scaling
- At ~12 bookings/sec average (120 peak), a single SQL primary handles the load comfortably. Optimistic locking keeps transactions short — no long-held row locks.
- If write scale becomes a concern: shard the
room_availabilitytable byhotel_idhash. All availability writes for a hotel go to one shard; no cross-shard join needed for a booking (a guest books one hotel per booking). - The
bookingstable can be sharded byuser_idso "my bookings" queries are single-shard. Cross-shard is only needed for hotel admin views (all bookings for my hotel) — route those to an analytics replica.
Fault tolerance
- Redis failure — if Redis is down, the booking service falls back to a DB-only flow: skip the Redis hold, use the DB-level constraint + optimistic lock as the sole guard. Slightly more DB load but functionally correct.
- Payment processor timeout — if Stripe's API times out during capture, retry with exponential backoff (the PaymentIntent ID ensures idempotency). Surface the booking as PENDING to the user until confirmed; the nightly reconciliation job catches any gaps.
- Kafka failure — bookings continue; Elasticsearch falls slightly behind (search may show sold-out rooms until Kafka recovers and the index catches up). The DB is always the source of truth — Elasticsearch is a downstream projection.
- DB primary failure — automatic failover to a standby replica (e.g., PostgreSQL with Patroni or Amazon RDS Multi-AZ). Brief read-only window during failover; new bookings queue and retry when the new primary is elected.
Step 15 — Why Not Cassandra for Bookings?
Unlike e-commerce order history (high volume, append-heavy, suitable for Cassandra archival), hotel booking volume is low enough that a SQL primary can retain the full booking history without a dedicated archival service. The correctness benefits of ACID transactions outweigh the scalability benefits of NoSQL at this data volume. Specifically:
- 1M bookings/day × 365 days × 500 bytes ≈ 180 GB/year — well within SQL's sweet spot.
- ACID multi-row updates (decrement availability across multiple dates + insert booking record in one transaction) are not natively supported by Cassandra's lightweight transactions (LWT are per-partition and limited).
- Cassandra's eventual consistency model would require complex application-level conflict resolution to prevent double-bookings — exactly the problem SQL's row-level constraints solve trivially.
Step 16 — Key Tradeoffs
| Decision | Choice | Trade-off accepted |
|---|---|---|
| Primary store | SQL throughout | Lower horizontal write scale than NoSQL; mitigated by the naturally low booking write rate |
| Concurrency control | Optimistic locking | Retry needed on conflict; under high contention for hot rooms, retry rate spikes — add exponential backoff |
| Search index | Elasticsearch (eventual) | Newly booked rooms may appear available in search for seconds until Kafka propagates; compensate with short-TTL availability cache |
| Checkout hold | Redis TTL (~10 min) | Room blocked for 10 min even if user abandons; mitigate with shorter TTL (5 min) and clear UI warning |
| Payment timing | Authorize now, capture at check-in | Authorization can expire (7 days) for far-future bookings; must re-authorize if needed |
| Analytics | Kafka → data warehouse | Analytics are eventually consistent (minutes to hours lag); acceptable for reporting use cases |
Hotel booking design is all about consistency: SQL + row-level constraints prevent double-booking at the database level; Redis TTL holds solve the checkout gap without permanently blocking inventory; optimistic locking keeps transactions short and highly concurrent; Kafka feeds Elasticsearch asynchronously to keep search accurate. The "why not NoSQL" answer is simple — booking volume doesn't justify sacrificing ACID, and hotel counts are bounded. The idempotency key on the booking API is the difference between a correct system and one that double-charges guests on network retries.
How do you prevent double-booking under concurrent requests? A CHECK (available_count >= 0) constraint on the room_availability table makes any transaction that would decrement below zero fail at the DB level. Optimistic locking with a version column ensures two concurrent bookings for the same room+date can't both succeed — one will retry with fresh data.
Why not use Cassandra for bookings like e-commerce uses it for order history? Hotel booking volume is low enough for SQL to retain full history; ACID transactions cleanly prevent double-bookings; Cassandra's eventual consistency model would require complex application-level conflict resolution.
What happens if a user abandons checkout after selecting a room? The Redis TTL (~10 min) expires automatically, triggering a background job (or keyspace notification handler) that re-increments available_count for each stay date — no manual cleanup or cron job needed.
How do you make the booking API idempotent? Require a client-generated Idempotency-Key header; store it in the bookings table as a UNIQUE column. A retried request with the same key returns the existing booking rather than creating a duplicate — preventing double-charges on network retries.
How do you handle the payment processor timing out during booking confirmation? Store the PaymentIntent ID in the booking record before making the capture call. Retry capture with exponential backoff using the same PaymentIntent ID (Stripe deduplicates). A nightly reconciliation job catches any booking in RESERVED state whose PaymentIntent has been captured — promotes them to BOOKED.