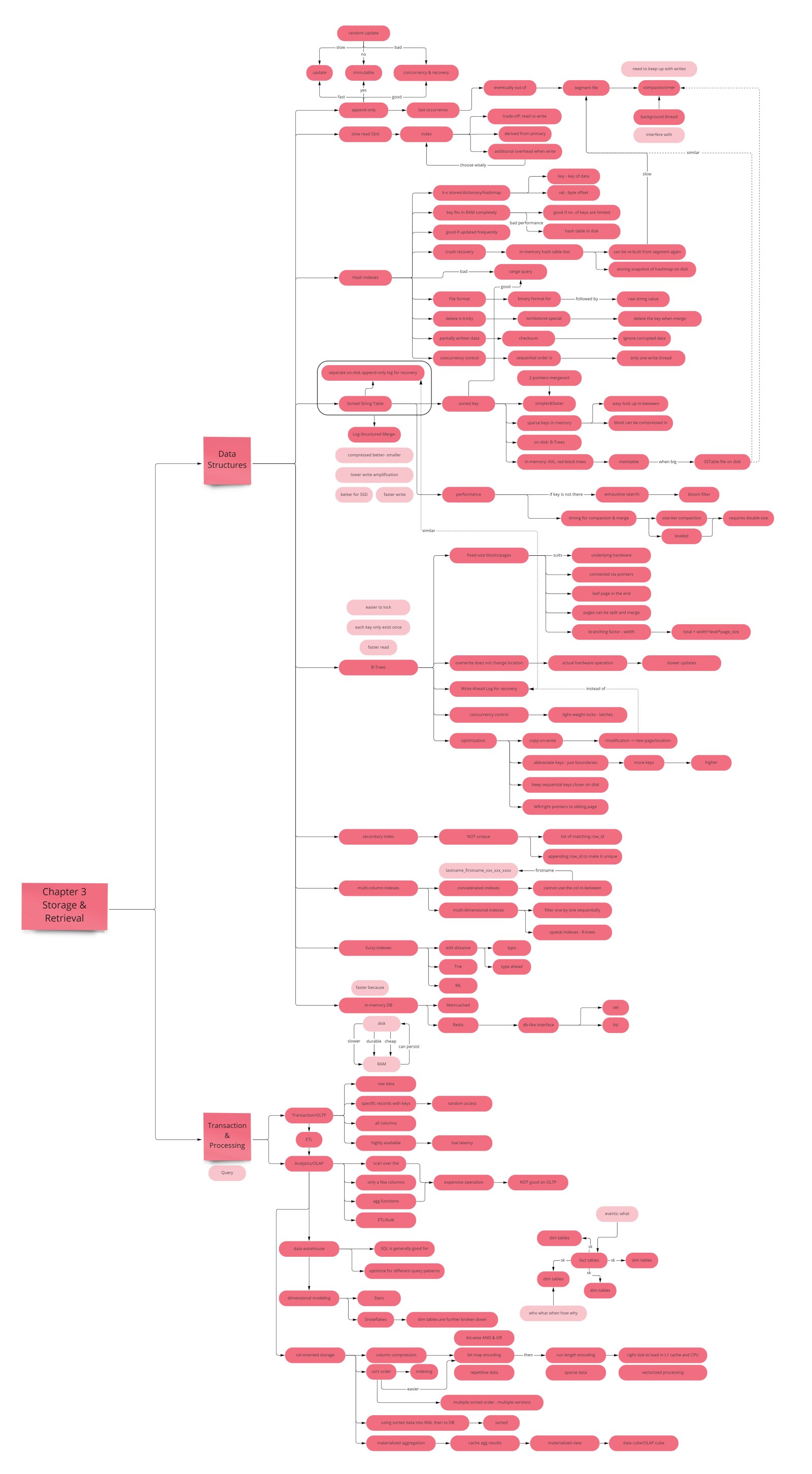
第 3 章回答每个后端工程师面试时都该能答的问题:"数据库到底如何存储和检索数据?"Kleppmann 走过两个根本不同的存储引擎家族,解释索引如何工作,然后转向数据仓库和列存储的分析世界。
- LSM-tree 偏向写——顺序追加到 memtable 再刷成 SSTable;布隆过滤器跳过不必要的磁盘读。Cassandra、RocksDB、HBase 使用。
- B-tree 偏向读——根到叶一条路径;原地页更新配 WAL 做崩溃恢复。PostgreSQL、MySQL/InnoDB、SQLite 使用。
- 预写日志(WAL)——B-tree 和 LSM-tree 都用 WAL 实现持久性;B-tree WAL 用于原地写的崩溃恢复;LSM-tree WAL 恢复未刷盘的 memtable。
- 聚簇 vs 非聚簇索引——聚簇把行数据存进索引叶(InnoDB 主键);非聚簇存指向 heap 文件的指针;覆盖索引(covering index)包含额外列以完全避开 heap 查找。
- OLTP vs OLAP 是根本不同的访问模式——OLTP:随机小点查;OLAP:跨数百万行的全顺序扫描。在分开的系统上跑它们。
- 列式存储——把一列的所有值存在一起;只读需要的列;激进压缩(bitmap、RLE、字典);支持 CPU SIMD 向量化执行。
LSM-tree(日志结构)偏向写;B-tree 偏向读。两者都用索引让查询快,但取舍不同。OLTP 数据库为随机访问点查优化;OLAP 仓库为顺序全列扫描优化。列式存储是让分析查询快的关键洞见。
原始笔记
本章总结所基于的手写学习笔记:
日志结构存储引擎
Kleppmann 从最底层建立直觉,从最简单可能的"数据库"开始——两个 bash 函数:
db_set() { echo "$1,$2" >> database; } # 仅追加
db_get() { grep "^$1," database | tail -n1 | cut -d',' -f2; }这个"数据库"有 O(1) 写(顺序追加到文件——最快可能的 I/O)和 O(n) 读(全扫描找最新值)。仅追加设计不是奇技——它是每个日志结构存储引擎的基础。追加到文件末尾是最高效的磁盘操作:它从不需要向后 seek、从不造成碎片,且崩溃安全(追加期间断电要么写入记录要么不写;它不会破坏先前写入的数据)。读问题正是索引要解决的。
哈希索引(Bitcask)
哈希索引是仅追加日志最简单的索引结构。Bitcask(Riak 默认存储引擎)在内存里维护一个从每个 key 到其在日志文件中最新值字节偏移的哈希 map。每次写追加一个新条目到日志并更新内存哈希 map 指针。每次读对存储的偏移做一次磁盘 seek 并加载值。无需扫描。
关键约束:整个 key 集必须装进 RAM。值可任意大、住在磁盘;只有 key 和偏移需要在内存。这个约束对有界数量的不同 key 但每 key 高更新率的负载可接受——想想 URL 短链(数百万 URL,各被点击和更新许多次)、IoT 传感器读数(数千传感器 ID、数百万时序值),或会话存储(固定用户数、频繁刷新的会话)。
日志文件无界增长,所以 Bitcask 把日志分段成最大尺寸的文件。compaction 作为后台进程运行:它读多个段文件,只保留每个 key 的最新值(丢弃同 key 的所有较早值),并写一个新的合并段文件。合并文件写完且内存哈希 map 更新后,旧段文件被删除。compaction 并发运行——读继续针对旧段,同时 compaction 写新段,然后一次原子指针交换过渡到新段。
崩溃恢复时,内存哈希 map 丢失。Bitcask 在重启时通过重放日志重建它——但这对大日志慢。优化是周期性把哈希 map 快照写到磁盘;重启时,加载快照并只重放自上次快照以来写入的段条目。
三个原因。第一,顺序写在机械盘上比随机写快得多,在 SSD 上仍显著更快(SSD 有写放大和磨损均衡特性,使随机写更昂贵)。第二,仅追加让并发更简单——更新同一位置的写者之间无争用。第三,崩溃恢复更干净——部分写入的追加在文件末尾,能被检测并丢弃;部分写入的原地更新让记录处于未知状态。
SSTable 与 LSM-Tree
有序字符串表(SSTable)给仅追加日志段加一个约束:每个段文件内的 key 必须有序。这单个约束解锁三个强大能力:
- 高效合并:合并多个段文件正是归并排序——从每个文件的有序 run 读第一个 key,把最小的写到输出,前进。O(n) 时间、常量内存。
- 稀疏内存索引:因为 key 有序,你只需每几 KB 一个内存索引条目。要找 key "home",查稀疏索引发现 "hand" 在偏移 1200、"how" 在偏移 1500——然后扫描中间的 300 字节。比每 key 一个条目小得多的内存占用。
- 范围查询:"apple" 和 "banana" 之间的 key 在有序文件里物理相邻——顺序读这个范围,而非每 key 发独立查找。
日志结构合并树(LSM-Tree),由 Patrick O'Neil 等人 1996 年描述、由 LevelDB(Google)、RocksDB(Meta/Facebook)、Apache Cassandra 和 Apache HBase 推广,通过以下生命周期维护 SSTable:
- 写进 memtable——一个内存平衡二叉搜索树(红黑树或跳表),始终保持 key 有序。写在内存里总是 O(log n),极快。
- WAL 实现持久性——每次写先追加到磁盘上的预写日志。若进程在 memtable 刷盘前崩溃,WAL 在重启时被重放以重建 memtable。memtable 成功刷盘后 WAL 被丢弃。
- 刷成 SSTable——当 memtable 超过阈值(通常几 MB),它作为新 SSTable 写到磁盘。因为 memtable 是有序树,产生的 SSTable 已经有序——无需额外排序遍。
- 读按顺序检查:先 memtable(当前写),再最新的磁盘 SSTable,再逐渐更旧的 SSTable。最近写的 key 会被快速找到;旧 key 可能需要检查多个 SSTable。
- 后台 compaction 合并并垃圾回收 SSTable,通过减少一次读必须检查的 SSTable 数,保持磁盘空间有界、读性能可接受。
布隆过滤器:避免不必要的磁盘读
LSM-tree 读有个根本弱点:对一个不存在的 key,读必须检查 memtable 和每个 SSTable(除非 key 能被快速排除)。对带频繁负查找的写多负载(如写前检查 key 是否存在),这很昂贵。布隆过滤器解决这个。
布隆过滤器是一个用位数组和多个哈希函数的概率数据结构。要加一个 key,计算 k 个哈希函数并把那 k 位设为 1。要查一个 key,计算同样 k 个哈希函数并检查那 k 位。若任何位是 0,该 key 一定不存在(无假阴性)。若所有位都是 1,该 key 可能存在(假阳性可能但由过滤器大小控制)。LSM-tree 每个 SSTable 挂一个布隆过滤器。当一次读需要检查某 SSTable,先咨询布隆过滤器——若它说"一定不在这里",该 SSTable 被完全跳过,省一次磁盘读。实践中这大幅降低不存在 key 的读放大。
compaction 策略:Size-Tiered vs Leveled
compaction 是合并 SSTable 以回收磁盘空间、降低读放大的后台进程。不同 compaction 策略做不同取舍:
| 策略 | 怎么工作 | 写放大 | 空间放大 | 使用者 |
|---|---|---|---|---|
| Size-tiered | 把相似大小的 SSTable 分组;达到阈值数量时合并组 | 较低——合并发生较少 | 较高——合并期间旧+新文件共存(临时最多 2× 空间) | Cassandra(默认)、HBase |
| Leveled | SSTable 组织进各 level;每 level 有大小上限;L0 从 memtable 刷出;某 level 满时 SSTable 合并进下一 level | 较高——数据跨 level 被重写 | 较低——每个 key 每 level 最多存在一次(L0 除外) | LevelDB、RocksDB、Cassandra(选项) |
Leveled compaction 保持每 level 总数据大小有界,意味着它更高效地用磁盘空间并提供更可预测的读性能(更少 level 要检查)。Size-tiered compaction 产生更少的总写,对写多负载更好,但代价是合并期间更高的空间放大。RocksDB 支持两种策略并允许为负载调优——这就是为什么它被用在 MyRocks(MySQL on RocksDB)、TiKV(分布式键值存储)和 CockroachDB(分布式 SQL)这些差异巨大的系统里。
B-Tree 存储引擎
B-tree 是关系数据库的主导索引结构。PostgreSQL、MySQL/InnoDB、SQLite、Oracle 和 SQL Server 都用 B-tree 作主索引结构。理解为什么需要理解 B-tree 被设计来解决什么问题、维护什么不变量。
结构与原地更新
不像把数据切成变长段文件的 LSM-tree,B-tree 把数据库切成固定大小的页(page)或块,传统是 4 KB——与磁盘扇区同大小,支持高效 I/O。树是平衡的:所有叶页在同一深度。叶页含实际键值对(或非聚簇索引指向 heap 文件位置的引用)。内部页(内部节点)含 key 和指向子页的指针。
当你查 B-tree,你从根页开始,找含你 key 的范围,跟随指针到合适的子页,重复直到到达叶。这个根到叶遍历是 O(log n) 但分支因子很高——一个 4 KB 页、4 字节 key 的深度 3 B-tree 能引用最多 256 TB 数据。实践中,深度 3–4 的 B-tree 对大多数生产数据库足够,意味着大多数读需要 3–4 次页读(或更少,因为上层几乎总在 buffer pool 里缓存)。
写原地更新页。要更新一个 key 的值,找含该 key 的叶页并覆写那页里的值。若插入一个新 key 而叶页满了,该页被分裂(split)成两页,父页被更新以含新的分隔 key。若父页也满,这个分裂能向上级联,最坏情况一路分裂到根并创建新根,使树高增一。B-tree 通过这个分裂机制保持平衡。
预写日志(WAL / Redo Log)
原地更新危险:若更新中途崩溃(如页分裂进行中),数据库可能处于不一致状态——分裂页存在但父指针未更新。B-tree 用预写日志(WAL)解决这个,某些系统里也叫 redo log。在修改任何页前,修改被写到磁盘上的仅追加 WAL 文件。若系统崩溃,WAL 在重启时被重放以把数据库带回一致状态。
WAL 在许多系统里也用于复制(PostgreSQL 的 WAL 流式复制、MySQL 的 binary log)。这种双用高效但在崩溃恢复和复制间制造耦合,使某些运维场景复杂化。
写放大是写到磁盘的字节数与写入的应用数据字节数之比。一次让 4 KB 页被写的单个键值写有 (4096 / 数据大小) 的写放大。对 B-tree,一个小更新强制写整页。LSM-tree 里的 compaction 让数据跨 level 被写多次。高写放大降低写吞吐并加速 SSD 磨损。这是为写多负载选 LSM-tree 的一个关键原因——顺序 compaction 写比随机 B-tree 页更新对 SSD 更友好。
LSM-Tree vs B-Tree:完整对比
| 属性 | LSM-Tree | B-Tree |
|---|---|---|
| 写路径 | 顺序追加到 memtable + WAL;周期性刷成 SSTable;后台 compaction | 随机原地页更新 + 每写一条 WAL 条目;偶尔页分裂 |
| 写放大 | 初次写较低;compaction 跨 level 重写数据多次 | 每次更新较高(写整页);随机小写在 SSD 上更糟 |
| 读性能 | 较慢——可能需检查 memtable + 多个 SSTable;布隆过滤器缓解不存在 key | 较快——确定性 O(log n) 根到叶路径;上层总被缓存 |
| 读放大 | 较高——一个 key 可能需检查多个 SSTable | 较低——任何 key 一条根到叶路径 |
| 空间放大 | compaction 期间较高(旧+新数据共存);墓碑直到被 compaction 清掉 | 较低——原地更新;空闲页由 B-tree 页分配器立即回收 |
| 压缩比 | 更好——有序、顺序布局压缩得好 | 更差——随机页布局带页分裂碎片 |
| 写延迟 | 更可预测(memtable 写)但 compaction 能造成延迟尖峰 | 页分裂期间能尖峰;对混合负载普遍良好 |
| 并发模型 | 更简单——SSTable 一旦写就不可变;无并发修改 | 复杂——页能被并发修改;需谨慎的 latch(短锁)管理 |
| 典型用例 | 写多负载、时序、事件日志、高量 IoT 数据摄取 | 读多或混合 OLTP;需要强读延迟保证的查询 |
| 示例系统 | Cassandra、RocksDB、HBase、LevelDB、ScyllaDB | PostgreSQL、MySQL/InnoDB、SQLite、Oracle、SQL Server |
对比不只是"LSM 用于写、B-tree 用于读"。真实负载是混合的,选择取决于写读比、key 分布、磁盘类型(SSD vs HDD)、延迟要求和运维复杂度容忍度。许多现代系统两者混用:RocksDB(LSM)被用作 MySQL(MyRocks)下的存储引擎以改善 SSD 上的写吞吐,同时保持 MySQL 的 SQL 接口。CockroachDB 内部用 RocksDB,同时暴露带 ACID 事务的完整 SQL。
主键之外的索引结构
二级索引
主索引把主键映射到一行——按定义每行唯一。二级索引把某个其他列(或列组合)的值映射到有该值的行。B-tree 和 LSM-tree 都能服务二级索引;数据结构相同,但 key 类型不同。
关键区别:二级索引值不唯一。city_id 上的索引可能把一个城市 ID 映射到数百万用户行。每个索引条目指向匹配行的列表(或一个 key 范围)而非单行。这通过在每个二级索引条目里包含主键(于是完整行通过第二次主键查找取)或直接指向 heap 文件位置(若行移动会变陈旧,需谨慎维护)来实现。
二级索引对查询性能至关重要——没有它们,任何在非主键列上过滤的查询都需要全表扫描。加二级索引大幅加速读,代价是写开销(每次插入或更新也必须更新所有二级索引)和存储空间。取舍显式且可测量,这就是为什么数据库 schema 设计涉及关于创建哪些二级索引的刻意决策。
聚簇 vs 非聚簇 vs 覆盖索引
这三个概念是数据库性能讨论和系统设计面试里被问得最多的索引细节之一。
在聚簇索引(clustered index)里,实际行数据物理存在索引结构本身内——具体在 B-tree 的叶页里。InnoDB(MySQL 默认存储引擎)总用主键作聚簇索引:主键 B-tree 就是表本身。按主键查一行是一次树遍历就交付完整行。每表只能有一个聚簇索引(因为数据只能按一种方式物理排序)。
在非聚簇索引(也叫 heap 文件索引)里,索引存一个键-指针对:被索引列值连同指向行在单独 heap 文件中位置的指针。按被索引列查找找到指针,然后对 heap 文件做第二次 I/O 取完整行。这是"双查找"——聚簇索引一次磁盘读而这里两次。若行移动(如页 compaction 期间)heap 文件指针也会变陈旧,需要更新索引。
覆盖索引(covering index)(或仅索引扫描)是一个优化:在二级索引里加被索引 key 之外的额外列,使查询能完全从索引回答而完全不碰 heap。若你最频繁的查询是 SELECT name, email FROM users WHERE city_id = 42,在 (city_id, name, email) 上建索引让查询引擎完全从索引满足查询。"被覆盖"的列冗余存储(它们也存在于 heap),但读更快因为消除了 heap I/O。
-- 非聚簇索引:city_id 上的索引,heap 查找取 name + email
CREATE INDEX idx_city ON users(city_id);
-- 读路径:city_id B-tree → heap 文件查找(2 次 I/O)
-- 覆盖索引:索引含 name + email;无需 heap 查找
CREATE INDEX idx_city_cover ON users(city_id, name, email);
-- 读路径:仅 city_id B-tree,name+email 从索引叶服务(1 次 I/O)
-- PostgreSQL:仅索引扫描的 EXPLAIN 输出
EXPLAIN SELECT name, email FROM users WHERE city_id = 42;
-- Index Only Scan using idx_city_cover on users
-- Index Cond: (city_id = 42)多列与模糊索引
多列索引(复合索引)覆盖多个列。索引先按前导列排序,再在每个前导列组内按后续列排序。查询 WHERE last_name = 'Smith' AND first_name = 'John' 能很高效地用 (last_name, first_name) 上的复合索引——它是一次有序范围查找。然而,单独的查询 WHERE first_name = 'John' 无法高效用那个索引(前导列缺失)——它需要全索引扫描。复合索引里的列顺序很重要,正确顺序取决于你的查询模式。
标准 B-tree 索引对结构化数据的精确匹配和范围查询高效。它们不适合全文搜索(需要理解词干、同义词、错别字)或近似查询。倒排索引(像 Elasticsearch 和 Lucene 用的)处理全文搜索:它们把每个词映射到含该词的文档列表,支持高效的逐词评分和布尔组合。对模糊匹配(找在 Levenshtein 编辑距离 k 内的字符串),用 BK-tree 或 SimHash 等专门结构。关键教训:正确的索引结构完全取决于查询类型,而不只是数据类型。
内存数据库
所有基于磁盘的存储引擎——B-tree 和 LSM-tree 皆然——都承担把应用数据结构编码成能存到磁盘、读时再解码回来的格式的成本。内存数据库完全绕开这个:权威数据集住在 RAM,内存数据结构的全部丰富性(哈希表、跳表、优先队列、树)无序列化开销即可用。
常见例子:Redis(键值、列表、集合、有序集合、哈希、流——全在内存,可选持久化)、Memcached(纯缓存、无持久化)、VoltDB(ACID 事务关系内存)、MemSQL/SingleStore(内存配磁盘支撑的持久性),和 Hazelcast(分布式内存数据网格)。
Kleppmann 提出一个常被误解的重点:内存数据库的性能优势不主要因为它们避开磁盘读——一个配置良好的磁盘数据库的工作集装进它的 buffer pool,反正很少碰磁盘。优势是它们避开把数据结构编码和解码成磁盘友好格式的开销。内存数据库能把 Redis 有序集合存为带真指针的真跳表;基于磁盘的系统需要在每次访问时序列化和反序列化它。产生的代码也常更快,因为内存数据结构能比其可序列化等价物更复杂、更高效。
内存数据库的持久性来自周期性磁盘快照(Redis RDB)、仅追加操作日志(Redis AOF)、同步复制到其他节点(VoltDB),或 NVM(非易失内存)硬件。"重启并重载"时间是真实的运维关切——一个有 100 GB 数据的 Redis 实例重启后可能需要数分钟从磁盘重载,期间不可用。
OLTP vs OLAP:两个不同世界
在线事务处理(OLTP)和在线分析处理(OLAP)代表驱动了不同存储架构的根本不同使用模式。理解两者——及为什么它们被分开——是数据工程里最重要的概念之一。
| 属性 | OLTP | OLAP |
|---|---|---|
| 主要用户 | 终端用户,通过应用 | 数据分析师、数据科学家、BI 工具 |
| 查询模式 | 点查和小更新;"订单 #12345 的状态是什么?" | 跨数百万行的聚合;"上季度按地区的总收入是多少?" |
| 每查询触及数据 | 几十到几百行 | 数百万到数十亿行 |
| 瓶颈 | 延迟——必须毫秒内响应;并发用户负载 | 吞吐——必须高效扫描海量数据;查询复杂度 |
| 写模式 | 随机、低延迟的单行插入/更新 | 批量 ETL 加载、事件流摄取——高量,常批处理 |
| 数据集大小 | GB 到 TB | TB 到 PB |
| Schema | 规范化,第三范式或更高 | 反规范化,为查询性能优化的星型或雪花 schema |
| 索引 | B-tree、频繁过滤列上的二级索引 | 列式存储;bitmap 索引;最少的行级索引 |
| 示例系统 | PostgreSQL、MySQL、Oracle、SQL Server | Amazon Redshift、Google BigQuery、Snowflake、Clickhouse、Apache Druid |
组织跑分开系统的原因是,为一种访问模式优化会主动损害另一种的性能。在 OLTP 数据库上跑分析查询占用连接池槽位、造成 buffer pool 抖动(分析扫描把 OLTP 工作集挤出缓存),并与延迟敏感的事务查询争 CPU 和 I/O。反之,OLTP 系统高度规范化的 schema 和行式存储不适合跨数百万行的分析聚合。
数据仓库与 ETL 管道
数据仓库是一个独立的读优化分析数据库,通过 ETL(抽取、转换、加载)管道按固定时间表从 OLTP 系统加载。抽取步骤从运营系统拉数据(常通过数据库复制或变更数据捕获)。转换步骤清洗、规范化并把数据重塑成仓库的 schema。加载步骤把数据插入仓库。
ETL 按时间表运行(每晚、每小时,或近实时)而非与 OLTP 写同步,引入传播延迟。晚上 11:59 做的一笔销售可能直到每晚 ETL 完成后才出现在仓库。现代"流式 ETL"架构(用 Kafka、Flink 或 Spark Streaming)把这个滞后降到秒或分钟级,支持近实时分析,但增加架构复杂度。
数据仓库暴露一个表面上类似 OLTP SQL 的 SQL 接口,但底层执行引擎根本不同——为大规模并行扫描而非索引点查构建。针对仓库写查询的 SQL 分析师无需理解这个区别;声明式查询接口隐藏它。这是声明式查询模型的伟大实践成功之一。
星型 Schema 与雪花 Schema
数据仓库里的主导 schema 模式是星型 schema。其中心是一张事实表(fact table),每行代表一个事件:一笔销售、一次点击、一次页面浏览、一次登录、一次广告展示。事实表通常是仓库里最大的表——数十亿行,每行代表一个业务事件的一次发生。每行含指向多个维度表(dimension table)(商品、客户、日期、门店、地理、活动)的外键和一个或多个数值度量(measure)(金额、数量、时长、收入)。
-- 星型 schema:事实表居中,维度向外辐射
CREATE TABLE fact_sales (
sale_id BIGINT,
date_key INT, -- FK → dim_date
product_key INT, -- FK → dim_product
customer_key INT, -- FK → dim_customer
store_key INT, -- FK → dim_store
quantity INT,
amount_cents BIGINT
);
-- 典型 OLAP 查询:跨数百万行、少数列的聚合
SELECT d.month, p.category, SUM(f.amount_cents) AS revenue
FROM fact_sales f
JOIN dim_date d ON f.date_key = d.date_key
JOIN dim_product p ON f.product_key = p.product_key
WHERE d.year = 2024 AND p.category = 'Electronics'
GROUP BY d.month, p.category
ORDER BY d.month;雪花 schema是一个变体,维度表被进一步规范化成子维度。例如,不用带 category_name 文本列的扁平 dim_product 表,雪花 schema 有一个带指向单独 dim_category 表外键的 dim_product 表。雪花 schema 更规范化(更少冗余、更小存储),但每查询需要更多 join。大多数分析查询引擎因此偏好星型 schema——更少 join、更简单的查询规划、更好的查询性能。
列式存储
分析系统最重要的存储洞见是列式存储——理解它为何重要需要理解分析查询的 I/O 模式。考虑一张有 100 列、10 亿行的事实表。一个典型 OLAP 查询可能触及其中 3–5 列,但必须为那些列扫描所有 10 亿行。行式存储(PostgreSQL、MySQL)里,数据布局为:行 1 的所有列,然后行 2 的所有列,等等。要为 10 亿行读 3 列,你必须从磁盘加载所有 10 亿行的全部 100 列——读你不需要的 97% 数据。
在列式存储(Redshift、Snowflake、ClickHouse、Vertica、Apache Parquet)里,数据布局为:所有行的列 1 的所有值,然后所有行的列 2 的所有值,等等。要为 10 亿行读 3 列,你只加载那 3 列——总数据的 3%。I/O 减少大约是 (需要的列 / 总列数)。对一张 100 列、查询触及 4 列的表,这是 25× 的 I/O 减少——对磁盘受限的分析负载是变革性改善。
列压缩
列存储支持激进压缩,因为每列含同类型的值且常只有少数不同值。压缩同时减少磁盘存储成本和从磁盘到 CPU 传输的数据量——进一步改善查询性能。主要技术:
- bitmap 编码:对低基数列(不同值相对行数少),为每个不同值建一个位向量,位 i 为 1 若行 i 有该值。一个跨 10 亿行有 50 个不同分类的
product_category列能表示为 50 个各 10 亿位的位向量——总共约 6 GB 而非约 4 GB 的 4 字节整数。真正的胜利:过滤(WHERE category = 'Electronics')等操作变成对位向量的按位 AND 操作,现代 CPU 用 SIMD 指令极高效地执行。 - 游程编码(RLE):当数据按该列排序,连续行常有相同值。RLE 把 N 个相同值的游程表示为对 (value, N)。一个按门店排序的
store_id列可能有 10000 行全是同一门店 ID 的游程。不存 10000 个整数,你存一个 (store_id, 10000) 对。这对高度重复的排序数据能减少存储 100–1000×,且使 GROUP BY 操作快得平凡(每个游程是一个组)。 - 字典编码:用一个小整数码替换每个不同值;存一个码到值映射的字典;把列存为整数码。对一个有 200 个不同值的
country_code列,用 1 字节码替换 2 字节字符串。字典编码被 Parquet、ORC 和大多数列格式使用。它也支持谓词下推:WHERE country = 'US'变成字典里的查找(找 'US' 的码),然后简单整数比较——每行无字符串解析。
向量化处理
压缩支持进一步优化:向量化执行(也叫 SIMD 向量化处理)。现代 CPU 有 SIMD(单指令多数据)指令集(SSE、AVX、AVX-512),同时对值向量操作——例如单个 AVX-512 指令能在一个 CPU 周期里把 16 个 32 位整数与一个常量比较。带压缩整数码的列式存储直接喂入 SIMD 操作:一个 bitmap 列能用每 64 行一条指令与另一个 AND。行式存储相反,需要每行在列类型上分支,妨碍 SIMD 优化。
列布局 + 压缩 + SIMD 向量化执行的组合,就是为什么 ClickHouse 或 BigQuery 上的分析查询在商用硬件上每秒扫描数十亿行——也是为什么行式存储引擎即便用强大得多的硬件也无法匹敌这个吞吐。
列存储里的排序顺序
列存储能为行选一个排序顺序,类比行式数据库里的聚簇索引。若行按 date_key 排序,那么带日期范围谓词的查询(WHERE date_key BETWEEN 20240101 AND 20240131)能用每列块的 min/max 统计跳过文件的大部分。排序也大幅改善排序 key 的 RLE 压缩:排序后的 date_key 值形成相同值的长游程(给定一天的所有交易),压缩得极好。
Vertica 把这个更进一步,跨不同副本存储多个排序顺序——一个按日期排序用于时间范围查询、另一个按地区排序用于地理聚合、另一个按 product_category 排序用于商品分析。读被路由到排序顺序最匹配查询的副本。这用存储(3 个排序顺序多 3× 数据)换跨多样查询模式的大幅更快查询性能——在存储相对查询时间便宜的分析系统里是个合理取舍。
物化视图与数据立方体
物化视图(materialized view)是一个预计算的查询结果,作为磁盘上真实表存储,而非每次访问时重算的虚拟视图。当底层表变化,物化视图必须刷新(要么每写时急切刷,要么周期性批处理)。OLAP 系统里,物化视图被激进用于预聚合昂贵计算。
一个特例是数据立方体(data cube,OLAP cube):事实表的多维预聚合视图。对 fact_sales 表,一个数据立方体可能预聚合每个 (month, category, store, region) 组合的收入——4 个维度。这允许那 4 个维度内的任何切片切块查询用单次查找而非全表扫描回答。取舍:立方体随维度数指数增长("维度灾难"),且底层数据变化时必须重建。对频繁查询、缓慢变化的数据(周或月聚合),数据立方体在传统 BI 系统里仍广泛使用。
现代云数据仓库(BigQuery、Snowflake)处理这个不同:不预算立方体,它们用大规模并行和列式存储让扫描快到物化不那么必要。但物化视图仍用于最频繁访问、最昂贵的聚合,那里即便并行扫描对交互式查询响应时间也太慢。
对 OLTP 写:LSM-tree 在写吞吐上胜 B-tree(顺序追加胜随机页更新,尤其在 SSD);B-tree 在读延迟和可预测性上胜 LSM(一条根到叶路径 vs 多个 SSTable 检查)。对分析:列式存储是近乎普遍的胜利——更少 I/O(只读需要的列)、更好压缩(列值同质且常重复),以及对压缩列块的 CPU SIMD 向量化执行。要知道数据仓库的星型 schema(事实表 + 维度表)是你在 BI 工具里写的每个分析查询的基础,而物化视图和数据立方体存在是为预先回答最昂贵的聚合。
LSM-tree vs B-tree——何时选哪个?写多负载用 LSM-tree(Cassandra、RocksDB):顺序 memtable 追加 + 后台 compaction 给更高写吞吐和更好压缩,尤其在 SSD。但读可能检查多个 SSTable——靠布隆过滤器缓解。读多或混合 OLTP 用 B-tree(PostgreSQL、MySQL):确定性 O(log n) 根到叶路径给快速可预测的读;写做带 WAL 持久性的随机页更新。对真正混合的负载,MySQL(MyRocks)下的 RocksDB(LSM)是流行混合。
什么是写放大、读放大、空间放大?写放大:写到磁盘的字节/应用数据字节(B-tree 的原地页写高;LSM compaction 跨 level 重写数据)。读放大:每次逻辑读所需的磁盘读(LSM 能检查许多 SSTable;B-tree 是一条路径)。空间放大:用的磁盘空间/逻辑数据大小(LSM compaction 期间有旧+新数据;B-tree 快速回收释放页)。
为什么列式存储让分析更快?一个 OLAP 查询触及可能数百列中的 3–5 列。行存储必须加载全部 100+ 列来抽取那几列。列存储只读需要的列——常是 10–30× 的 I/O 减少。结合 bitmap/RLE/字典压缩(列值重复)和对压缩块的 CPU SIMD 向量化操作,I/O 和 CPU 周期都大幅减少。
什么是布隆过滤器、为什么 LSM-tree 用它?一个无假阴性的概率数据结构:若布隆过滤器说"key 一定不在这里",该 key 保证缺席。LSM-tree 每个 SSTable 挂一个,以对不可能含被查 key 的 SSTable 跳过磁盘读——对降低负查找的读放大至关重要。
什么是预写日志、为什么 B-tree 和 LSM-tree 都需要它?WAL 是在任何数据修改前写的仅追加持久性日志。B-tree 用它从打断原地页更新(让页部分修改)的崩溃中恢复。LSM-tree 用它在崩溃后恢复未刷盘的 memtable(memtable 内容从 RAM 丢失;WAL 重放它们)。两种情况下,WAL 都是近期写的真相来源,直到它们被持久提交到主数据结构。