A load balancer sits between clients and a pool of backend servers, distributing incoming traffic so no single server becomes a bottleneck. It is the cornerstone of horizontal scalability: add more servers and the load balancer spreads the work automatically. Without one, scaling out is operationally impossible and a single server failure takes down the entire service.
- Layer 4 vs Layer 7 — L4 routes on TCP/UDP headers (fast, no content inspection); L7 routes on HTTP path/headers/cookies (smarter, slightly more CPU).
- Round Robin works well for uniform workloads; Least Connections adapts to variable-duration requests.
- IP Hash gives session affinity without storing state, but reshuffles all clients when a server is removed.
- Sticky sessions are a workaround for stateful servers — the real fix is externalizing session state to Redis.
- LB redundancy — run active-passive or active-active pairs with a VIP; the LB itself must not be a SPOF.
Load balancers route traffic across backend servers using algorithms like round-robin, least connections, or IP hash. Layer 4 LBs route on TCP/UDP metadata; Layer 7 LBs inspect HTTP content and can make smarter routing decisions. Health checks automatically remove unhealthy servers from the pool.
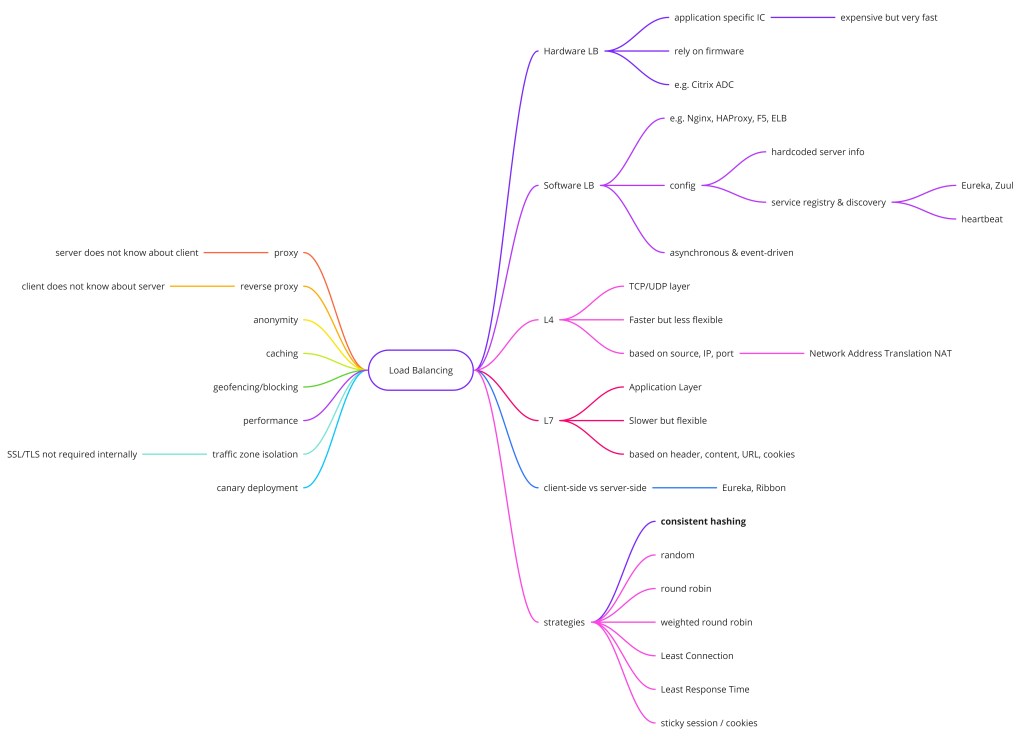
Why Load Balancing?
Three core problems it solves:
- Throughput — a cluster of smaller servers can handle more total requests than one large server, and is cheaper to scale incrementally.
- High availability — when a server fails, the load balancer detects it via health checks and stops routing traffic to it, typically within seconds.
- Reduced latency — geographic load balancers can route users to the nearest data center, cutting round-trip time.
Layer 4 vs. Layer 7
| Dimension | Layer 4 (Transport) | Layer 7 (Application) |
|---|---|---|
| Works on | TCP/UDP headers (IP + port) | HTTP headers, URL, cookies, body |
| Performance | Very fast — no content inspection | Slightly higher CPU cost |
| Routing intelligence | Low — no awareness of application protocol | High — can route by path, host, or header value |
| TLS termination | Pass-through only | Can terminate TLS, inspect payload, re-encrypt |
| Examples | AWS NLB, HAProxy TCP mode | AWS ALB, Nginx, Envoy |
In practice, most modern architectures use Layer 7 load balancers at the edge (for HTTP routing, TLS termination, and header manipulation) and Layer 4 load balancers for internal TCP services where raw throughput matters more than routing intelligence.
Load Balancing Algorithms
Round Robin
Requests are distributed sequentially across the server pool in a circular order. Simple and effective when all servers have identical capacity and request cost is uniform. Weighted Round Robin extends this by assigning a weight to each server proportional to its capacity, so a server with weight 3 receives three times as many requests as one with weight 1.
Least Connections
Each new request goes to the server currently handling the fewest active connections. This adapts naturally to workloads with variable request duration — a server processing a long-running query holds fewer new connections. Weighted Least Connections divides the active connection count by the server's weight before comparing.
IP Hash
The client's IP address is hashed to deterministically select a server. The same client always lands on the same backend, providing session affinity without requiring the load balancer to store session state. The downside: if one server is removed, all its clients are re-hashed and reassigned, potentially disrupting in-flight sessions.
Random
A server is selected uniformly at random. Statistically approaches round-robin with large request volumes, but with no guarantees for small volumes. Useful when you want zero coordination overhead and the pool is large and homogeneous.
Health Checks
Load balancers probe backends at regular intervals to detect failures. A server is marked unhealthy after a configurable number of consecutive failures and removed from the pool. It is re-added once a configurable number of consecutive checks pass. There are two flavors:
- Passive health checks — infer health from actual traffic. If a server returns 5xx errors, the LB marks it degraded.
- Active health checks — the LB sends synthetic probe requests (TCP handshake, HTTP GET to
/health) on a schedule, independent of real traffic.
upstream backend {
least_conn; # least-connections algorithm
server 10.0.0.1:8080 weight=3;
server 10.0.0.2:8080 weight=1;
server 10.0.0.3:8080 backup; # only used if primary servers fail
}
server {
listen 80;
location / {
proxy_pass http://backend;
proxy_next_upstream error timeout http_500;
}
}Sticky Sessions
Some applications store session state on the server (in-process caches, file uploads in progress). Sticky sessions (also called session persistence) ensure that a given client's requests always go to the same backend. The load balancer typically implements this by setting a cookie on the client's first request and reading it on subsequent ones.
Sticky sessions are a double-edged sword: they improve compatibility with stateful applications but reduce the even distribution of load and complicate failure handling — if the sticky server goes down, all its sessions are lost anyway. The preferred fix is to move session state to a shared store (Redis, a database) so any server can handle any request.
Load Balancer Redundancy
The load balancer itself is a potential single point of failure. Production deployments use an active-passive or active-active pair, often with a Virtual IP (VIP) address that floats between nodes. DNS or BGP routes the VIP to the active node; if it fails, the passive node claims the VIP within seconds via protocols like VRRP (HAProxy + Keepalived) or by updating the DNS record.
Consistent Hashing
IP Hash and simple modulo-based routing share a catastrophic flaw: adding or removing a server reshuffles nearly all client assignments. If you have 10 servers and add one, modulo 11 produces completely different targets for most keys — suddenly 90% of your cache keys miss on the new server mapping, causing a thundering herd on the backends. Consistent hashing solves this by mapping both servers and requests onto a circular hash ring, so that adding or removing one server affects only the keys in the range between it and its nearest neighbor — roughly 1/n of keys for n servers.
How the Ring Works
Each server is hashed to one or more points on a 0–2³²−1 ring. Each request key is also hashed to a point on the ring; the request is routed to the first server encountered moving clockwise from that point. With virtual nodes (vnodes), each physical server occupies multiple points on the ring (e.g., 150 vnodes per server), which smooths out the uneven distribution that occurs when server hashes cluster in one region of the ring.
import hashlib, bisect
class ConsistentHashRing:
def __init__(self, nodes, vnodes=150):
self.ring = {} # hash → node
self.keys = [] # sorted hash values
for node in nodes:
for i in range(vnodes):
h = self._hash(f"{node}-{i}")
self.ring[h] = node
self.keys.append(h)
self.keys.sort()
def _hash(self, key):
return int(hashlib.md5(key.encode()).hexdigest(), 16)
def get_node(self, key):
h = self._hash(key)
idx = bisect.bisect(self.keys, h) % len(self.keys)
return self.ring[self.keys[idx]] # clockwise successorConsistent hashing is used by: distributed caches (Memcached, Redis Cluster), CDN edge servers, database sharding routers, and Kafka's partition assignment. It is the answer whenever session affinity or cache locality matters and you need to add/remove nodes without catastrophic key remapping.
L4 vs L7 — Going Deeper
The high-level distinction is well known, but the implementation details determine which you should reach for in each scenario.
Layer 4 Under the Hood
An L4 load balancer operates at the TCP/UDP transport layer. It sees source IP, destination IP, source port, and destination port — and nothing else. The two dominant forwarding strategies are:
- NAT mode — the LB rewrites the destination IP to the chosen backend's IP and the source IP to its own address, so the backend replies to the LB, which translates back. Simple but adds one network hop.
- Direct Server Return (DSR) — the LB rewrites only the destination MAC address (or uses tunneling) so the backend responds directly to the client, bypassing the LB on the return path. Response traffic (which is typically 10–100× the request traffic for HTTP) never touches the LB. This is how Google's Maglev and Facebook's IPVS-based LBs achieve million-packet-per-second throughput — by keeping the LB entirely out of the high-volume return path.
Layer 7 Under the Hood
An L7 load balancer terminates the TCP connection from the client, reads the HTTP/gRPC/WebSocket request, makes a routing decision based on content, and establishes a separate TCP connection to the backend. This two-connection model is what enables features that L4 cannot provide:
- Request-level routing —
POST /api/orders→ order service;GET /api/products→ product service. - Header manipulation — add
X-Request-ID, rewriteHost, strip internal headers before sending to backends. - TLS termination — decrypt at the LB (or service mesh sidecar), inspect the plaintext, optionally re-encrypt to backend (TLS origination). Centralizes certificate management.
- Authentication offload — validate JWTs or API keys at the LB, forward only authenticated requests to backends.
- Rate limiting and circuit breaking — count requests per client/API key and reject excess before they reach backends.
- gRPC load balancing — L4 LBs can't balance individual gRPC calls within a long-lived HTTP/2 connection; only an L7 proxy that understands HTTP/2 framing can distribute calls across backends.
gRPC multiplexes many calls over a single long-lived HTTP/2 connection. An L4 load balancer routes the entire connection to one backend — all calls on that connection land on the same server, completely defeating load balancing. The fix is an L7-aware proxy (Envoy, Nginx with gRPC proxy module, Linkerd) that can distribute individual gRPC frames across backends.
SSL/TLS Termination Strategies
There are three standard approaches to TLS in a load-balanced architecture, each with different security and performance tradeoffs:
| Strategy | Description | Pros | Cons |
|---|---|---|---|
| TLS Termination at LB | LB decrypts traffic; backend receives plain HTTP | Centralized cert management; LB can inspect/route on content; backends simpler | Internal traffic unencrypted; LB is a decryption oracle |
| TLS Pass-through (L4) | LB forwards encrypted bytes; backend terminates TLS | End-to-end encryption; LB never sees plaintext | No L7 routing possible; cert management per backend |
| TLS Re-encryption | LB terminates TLS from client, then opens a new TLS connection to backend | Both segments encrypted; LB can inspect and route | Higher CPU cost; two cert pairs to manage |
Most cloud architectures use TLS termination at the edge LB (AWS ALB, Cloudflare) combined with internal mTLS (mutual TLS between services, enforced by a service mesh like Istio or Linkerd). This gives you L7 routing at the edge, centralized public cert management, and end-to-end encryption without hand-managing backend certificates.
# TLS termination + re-encryption to backends
server {
listen 443 ssl;
ssl_certificate /etc/ssl/certs/api.example.com.crt;
ssl_certificate_key /etc/ssl/private/api.example.com.key;
ssl_protocols TLSv1.2 TLSv1.3;
ssl_ciphers ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES128-GCM-SHA256;
location / {
proxy_pass https://backend; # re-encrypt to backends
proxy_ssl_verify on;
proxy_ssl_trusted_certificate /etc/ssl/certs/internal-ca.crt;
proxy_ssl_session_reuse on; # reuse TLS sessions for perf
}
}Health Checks — Advanced Configuration
Basic health checks send a TCP SYN or an HTTP GET to /health. In production, the gap between "the process is alive" and "the process can serve production traffic" is where most failures hide. Advanced health check design closes this gap.
Health Check Endpoint Design
A well-designed /health endpoint should check all critical dependencies — database connectivity, cache availability, downstream service reachability — and return structured JSON with per-dependency status. This lets a load balancer distinguish between "server completely dead" (TCP failure) and "server alive but database is down" (HTTP 503), and route accordingly.
// GET /health/readiness — 200 OK if ready, 503 if not
{
"status": "degraded",
"checks": {
"database": { "status": "up", "latency_ms": 3 },
"cache": { "status": "up", "latency_ms": 0.5 },
"payment_gw":{ "status": "down", "latency_ms": 5000 }
}
}HAProxy Health Check Configuration
backend api_servers
balance leastconn
option httpchk GET /health/readiness
http-check expect status 200
default-server inter 5s fall 3 rise 2 # check every 5s; 3 failures = down, 2 successes = up
server api1 10.0.0.1:8080 check weight 10
server api2 10.0.0.2:8080 check weight 10
server api3 10.0.0.3:8080 check weight 5 # smaller instance — half the weight
server api4 10.0.0.4:8080 check backup # only activated if all primary servers failDNS Load Balancing and Global Traffic Management
DNS-based load balancing operates above the network layer entirely: the DNS server returns different A records to different clients, distributing them across server pools or geographic regions. It is the foundation of global traffic management and multi-region deployments.
How DNS LB Works
The authoritative DNS server for your domain returns different IP addresses based on a policy — simple round-robin across IPs, or geographic routing based on the resolver's IP. Clients cache the response for the TTL duration (often 30–300 seconds), then re-resolve. This creates a natural load distribution at the DNS layer, before any TCP connection is made.
# Simple DNS round-robin: return different IPs on successive queries
api.example.com. 30 IN A 54.1.2.3 # US-East LB VIP
api.example.com. 30 IN A 52.4.5.6 # US-West LB VIP
api.example.com. 30 IN A 13.7.8.9 # EU-West LB VIP
# DNS TTL = 30s: clients cache for 30s, then re-resolve to a different IP
# Low TTL enables fast failover but increases DNS query loadLimitations of DNS LB
- TTL caching — clients and intermediate resolvers cache DNS responses for the TTL. If a server goes down, clients who cached its IP will try to reach it for up to TTL seconds before getting the updated record. Setting TTL=0 helps but many resolvers ignore it.
- No connection state — DNS knows nothing about server load, connection counts, or response times. A server that is alive but overloaded continues to receive its share.
- Sticky by default — long-lived applications resolve once and cache the result in their own connection pool. They won't re-resolve for hours regardless of the TTL.
GeoDNS and Latency-Based Routing
Services like AWS Route 53, Cloudflare, and Akamai extend DNS with geographic intelligence: they identify the resolver's location (typically proxy for the user's location) and return the IP of the nearest healthy endpoint. A user in Europe resolves api.example.com to a Frankfurt IP; a user in Singapore resolves to a Singapore IP. Combined with health checks that remove unhealthy endpoints from rotation, GeoDNS provides region-level failover in addition to latency optimization.
Anycast and Global Load Balancing
Anycast is a routing technique where the same IP address is announced from multiple geographic locations simultaneously via BGP. The Internet's routing protocol naturally delivers packets to the topologically closest origin — traffic from Europe reaches a European PoP, traffic from Asia reaches an Asian PoP, all to the same destination IP address. This is how CDNs and DDoS scrubbing services work: a single IP address appears at hundreds of edge locations.
Anycast differs from DNS LB in an important way: the routing decision is made at the network layer (BGP), not the application layer. There is no TTL caching problem — packets are routed to the nearest PoP at every hop. And because BGP re-converges within seconds when a PoP fails, failover is faster and more reliable than waiting for DNS TTLs to expire.
Cloudflare operates the same IP address (e.g., 1.1.1.1 for their DNS resolver, or their anycast network for CDN) from 300+ data centers worldwide. A user in Tokyo connects to a Tokyo edge node; a user in São Paulo connects to a São Paulo edge node — all to the same IP. This is Anycast at scale: global load distribution and fault tolerance with a single IP address.
Session Persistence Deep Dive
Sticky sessions come in several implementation variants with meaningfully different tradeoffs. Understanding them matters for both production operations and interview discussions about stateful applications.
Cookie-Based Affinity
The load balancer sets a cookie (e.g., SERVERID=api2) on the client's first request. On subsequent requests, the LB reads the cookie and routes to the designated backend. This is the most common and flexible approach — it works across IP changes (mobile clients switching networks), doesn't expose backend IPs, and the cookie TTL controls how long affinity persists.
backend web_servers
balance roundrobin
cookie SERVERID insert indirect nocache # LB-managed sticky cookie
server web1 10.0.0.1:80 check cookie web1
server web2 10.0.0.2:80 check cookie web2
server web3 10.0.0.3:80 check cookie web3IP Hash Affinity
Hash the client IP to select a backend deterministically. No cookie overhead, but mobile clients roaming between networks get reassigned, and corporate clients (many users behind one NAT IP) all land on the same backend. Adding or removing a server changes the hash result for a fraction of clients proportional to 1/n (assuming consistent hashing) or almost all clients (naive modulo).
The Right Fix: Externalize Session State
Both approaches are workarounds for a deeper problem: session state stored in the application server's memory. The production-grade solution is to move session state to a shared, fast store like Redis or Memcached. Any backend can then handle any request because the session is looked up from the external store, not local memory. This enables truly elastic horizontal scaling: add or remove servers without any client-visible disruption.
High Availability and Failover Patterns
A load balancer that itself has a single point of failure has solved the wrong problem. Production LB setups use one of two high-availability patterns.
Active-Passive with VIP
Two load balancer nodes share a Virtual IP (VIP) address. Under normal operation, only the active node claims the VIP and handles all traffic. The passive node monitors the active via heartbeat (VRRP, keepalived). If the active fails to send a heartbeat within a configurable window, the passive claims the VIP via gratuitous ARP and takes over. Failover typically completes in 1–2 seconds. AWS Elastic Load Balancer, Google Cloud LB, and Azure Load Balancer manage this internally — you never see the VIP mechanics.
# keepalived.conf (VRRP active-passive LB pair)
vrrp_instance VI_1 {
state MASTER # set BACKUP on the passive node
interface eth0
virtual_router_id 51
priority 110 # higher priority = preferred master; BACKUP = 100
advert_int 1 # VRRP heartbeat every 1s
authentication {
auth_type PASS
auth_pass secret123
}
virtual_ipaddress {
203.0.113.10 # the VIP both nodes compete for
}
track_script {
chk_haproxy # demote if haproxy process dies
}
}Active-Active
Both LB nodes handle traffic simultaneously, typically via DNS round-robin between two VIPs or via an upstream Anycast address. Total throughput is doubled. On failure, the surviving node absorbs all traffic. The tradeoff: slightly more complex configuration and state synchronization (connection tables must be replicated if TCP sessions are to survive failover seamlessly).
Algorithm Comparison and Selection Guide
| Algorithm | Best for | Weakness | Complexity |
|---|---|---|---|
| Round Robin | Uniform request cost, identical servers | Uneven if requests vary in duration or server capacity differs | O(1) |
| Weighted Round Robin | Heterogeneous server capacities | Still ignores current server load; static weights need manual tuning | O(1) |
| Least Connections | Variable request duration (long-polling, streaming) | All new connections sent to an idle server simultaneously (thundering herd on recovery) | O(log n) |
| IP Hash | Session affinity without cookie overhead | Reshuffles on server add/remove; NAT clients create hot spots | O(1) |
| Consistent Hash | Session affinity + cache locality at scale | Slightly uneven distribution without vnodes; more implementation complexity | O(log n) |
| Random | Very large homogeneous pools with stateless requests | No guarantees for small pools; no awareness of server load | O(1) |
| Least Response Time | Latency-sensitive APIs; weighted by actual response speed | Requires active measurement overhead; can amplify thundering herds | O(log n) |
Load Balancing in Modern Architectures
Service Mesh
In microservices architectures, a service mesh (Istio, Linkerd, Consul Connect) moves load balancing logic from a central LB appliance into a sidecar proxy (typically Envoy) running alongside every application Pod. Each sidecar intercepts all inbound and outbound traffic, applies load balancing, retries, circuit breaking, and mTLS — without the application code knowing. The control plane (Istio's istiod, Linkerd's control plane) distributes configuration updates to all sidecars.
The advantage: L7 load balancing with per-request routing decisions at every service-to-service call, not just at the edge. The cost: every Pod now has a sidecar consuming ~50–100 MB RAM and adding ~1–2 ms latency per hop.
AWS Application Load Balancer — Key Features
- Content-based routing — route by path (
/api/*→ ECS service), host header, query string, or HTTP method. - Target group weighting — send 10% of traffic to a new service version for canary deployments.
- Lambda targets — route specific paths to Lambda functions, mixing containerized and serverless backends behind one LB.
- WebSocket and HTTP/2 support — ALB is connection-aware enough to maintain long-lived WebSocket connections and distribute HTTP/2 streams.
- WAF integration — attach AWS WAF to block common attack patterns at the LB before traffic reaches backends.
Common Pitfalls and Best Practices
- Never forget the LB is a SPOF — run active-passive or active-active pairs. A single LB in front of 100 highly-available backends makes the architecture no more available than the LB itself.
- Health check what matters, not just TCP port open — a process can be listening on port 8080 while its database connection pool is exhausted. Check
/health/readiness, not just TCP SYN. - Set connection draining (deregistration delay) — when removing a backend from the pool, allow in-flight requests to complete (typically 30–300 seconds) before closing connections. AWS ALB calls this "deregistration delay"; Nginx calls it
proxy_next_upstreamcombined with graceful shutdown. - Low TTL for DNS LB does not equal instant failover — resolvers ignore TTL floors, browsers cache, OS stub resolvers cache. Budget 60–120 seconds for DNS changes to fully propagate even with 30-second TTLs.
- Monitor backend queue depth, not just connection count — least-connections algorithms route to the server with fewest connections, but a server processing slow 30-second DB queries has fewer connections than one serving fast 50ms requests. Least-response-time or a queue-depth metric is more accurate for latency-sensitive tiers.
- Separate health check traffic from production traffic — a noisy health check hammering
/healthevery second to 50 backends generates 50 req/sec of load. Use a lightweight endpoint that does minimal work, and cache dependency check results for a few seconds.
Choose Layer 7 for HTTP workloads that need path routing, TLS termination, or header inspection. Choose Layer 4 for raw TCP throughput, non-HTTP protocols, or extreme performance via Direct Server Return. Pick your algorithm based on request homogeneity: round-robin for uniform workloads, least-connections for variable ones, consistent hash for cache locality and session affinity. Always run at least two load balancers in active-passive or active-active configuration to avoid introducing the very SPOF you set out to eliminate.
Layer 4 vs Layer 7 — when do you pick each? Layer 4 for raw TCP throughput, non-HTTP protocols, or when you need Direct Server Return to keep return traffic off the LB; Layer 7 when you need path-based routing, TLS termination, gRPC support, or header-based decisions.
How does a load balancer detect a failed server? Active health checks (synthetic probes to /health on a schedule) or passive health checks (infer from 5xx error rates on real traffic). Active checks detect pre-traffic failures; passive checks detect in-flight failures.
Why are sticky sessions a problem? They reduce load distribution, complicate scaling, and mean all session data is lost if that server goes down — the fix is externalizing session state to Redis so any server can handle any request.
What is consistent hashing and when is it used? Maps servers and requests to a ring; adding/removing a server affects only ~1/n of keys instead of reshuffling everything. Used by distributed caches, CDNs, database sharding, and Kafka partition assignment.
How does Anycast work? The same IP is announced via BGP from multiple geographic PoPs; the Internet's routing naturally delivers packets to the topologically nearest PoP — no DNS resolution, no TTL caching, sub-second failover when a PoP goes down.
Why can't an L4 LB balance gRPC traffic? gRPC multiplexes many calls over a single HTTP/2 connection; an L4 LB routes the entire connection to one backend. Only an L7 proxy that understands HTTP/2 framing can distribute individual calls across backends.