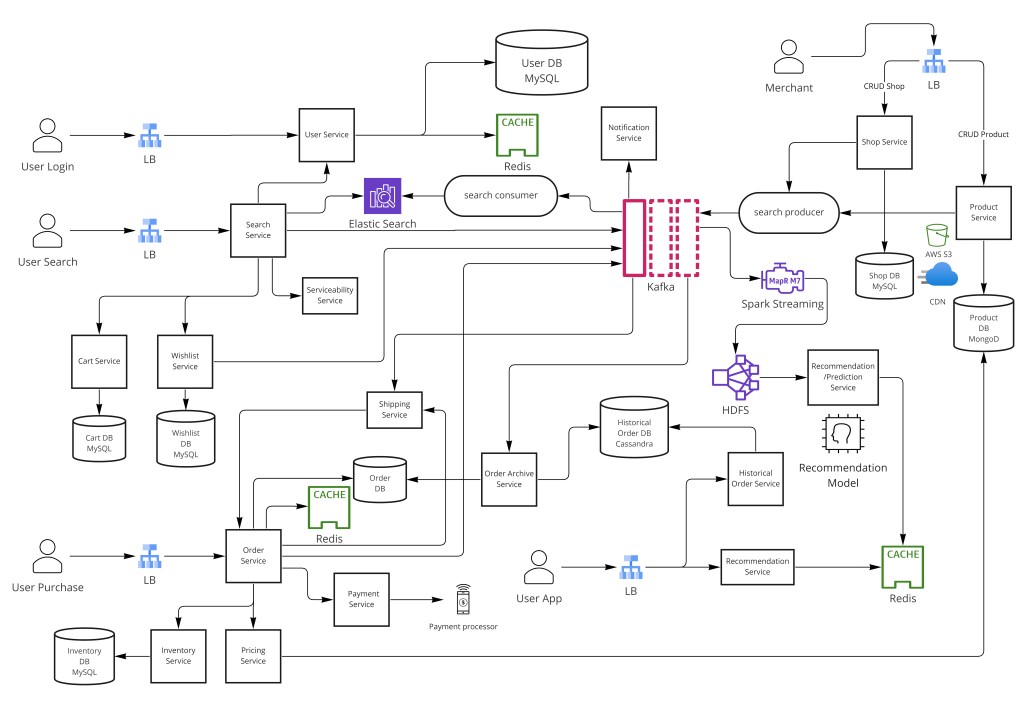
电商平台——想想 Amazon、阿里巴巴、Walmart 或 Shopify——是面试中可能被要求设计的最苛刻的分布式系统之一。它同时结合实时库存管理、金融交易处理、高流量搜索与发现,以及 ML 驱动的个性化,全都在严格正确性要求下——一个超卖的商品或一个丢失的订单直接转化为损失的收入和破碎的用户信任。本指南走完整个面试弧:需求、容量估算、API 与数据建模、高层架构,然后深入真正难的部分——结账、库存、支付、搜索、扩展和容错。
- 微服务 + API 网关——每个服务拥有自己的数据存储;无跨服务直接 DB 访问。
- 钱用 SQL,目录用 NoSQL——订单/用户用 ACID;异构商品 schema 用文档存储。
- Redis 购物车持有(TTL ~10 分钟)——软预留库存而不永久阻塞;过期自动释放。
- Kafka 解耦结账——用户得到即时确认;库存扣减、支付和通知在下游异步发生。
- CDC → Elasticsearch——搜索索引保持最终一致而不把写延迟耦合到索引。
- Cassandra 做归档——横向可扩展、高写吞吐用于历史订单记录。
- 处处幂等——支付键、事件消费者去重,和跨服务一致性的 Saga 模式。
用 API 网关后的微服务:订单和用户用 SQL(ACID),商品目录用 NoSQL(schema 灵活),历史订单归档用 Cassandra,购物车持有用带 TTL 的 Redis,Kafka 把结账管道与下游处理解耦。Elasticsearch 经 CDC 喂的索引驱动搜索。在要紧处(钱、库存)保持一致,其他处拥抱最终一致。
第 1 步 — 澄清需求
画一个框前,大声界定问题。面试官奖励把一个宽得不可能的提示收窄成一个具体、可辩护的子集。电商很大,所以陈述你会和不会覆盖什么。
功能需求
- 用户注册、认证和资料管理。
- 商家入驻:店铺创建和商品管理(带媒体的 CRUD)。
- 商品搜索、浏览、购物车和愿望单。
- 结账和支付,产生一个持久订单。
- 个性化首页 feed 和订单历史。
- 订单生命周期跟踪(下单 → 已付 → 已发货 → 已送达)。
非功能需求
- 低延迟——搜索和页面加载 ~200 ms p99 内;结账应感觉即时。
- 高可用——目标 99.99%;高峰销售(Prime Day、双 11)期间宕机是灾难性的。
- 要紧处强正确性——库存绝不能超卖;支付绝不能双重扣款。
- 可扩展——挺过闪购期间 10–100× 流量尖峰。
- 持久性——一个已确认订单绝不丢失。
显式命名什么是范围外——推荐排序内部、欺诈检测、卖家分析套件——这样你能把时间花在核心事务路径上。说"我把支付处理当作经 webhook 的外部提供商"是一个界定范围的决定,不是缺口。
第 2 步 — 容量估算
粗略数字证明你的存储和扩展选择。假设一个有 1 亿日活(DAU)的大平台。
流量
- 若每 DAU 每天执行 ~10 次读动作(浏览/搜索):100M × 10 = 1B 读/天 ≈ 11,500 读/秒平均,5× 峰值因子约 ~58K 读/秒峰值。
- 若 1% DAU 每天下单:1M 订单/天 ≈ ~12 写/秒平均,但闪购能把那集中到几分钟——为突发 数千订单写/秒设计。
- 读写比大约 100:1,这呐喊"激进缓存并用读副本"。
存储
- 500M 商品 × 各 ~2 KB 元数据 ≈ 1 TB 目录数据(媒体前)。
- 商品图片/视频住在 CDN 后的对象存储(S3)——轻易 PB 级,挡在主 DB 外。
- 订单:1M/天 × 365 × ~1 KB ≈ ~365 GB/年热订单数据,线性增长——历史订单归档到 Cassandra 的原因。
你不需要确切数字——你需要正确的数量级和它们驱动的结论:100:1 读写比 → 缓存 + 副本;PB 级媒体 → 对象存储 + CDN;线性增长的订单 → 一个归档层。
第 3 步 — API 设计
通过 API 网关暴露干净的 REST 面。几个代表性端点:
# 目录与搜索
GET /api/products?q=shoes&category=men&page=2
GET /api/products/{productId}
# 购物车(软预留库存)
POST /api/cart/items { productId, qty }
DELETE /api/cart/items/{id}
# 结账——经客户端提供的键幂等
POST /api/orders
Idempotency-Key: "a1b2-c3d4"
{ cartId, addressId, paymentMethodId }
GET /api/orders/{orderId}两个赢得加分的细节:结账端点携带一个 Idempotency-Key,使重试请求(不稳定移动网络、双击)绝不创建重复订单;搜索支持 cursor/offset 分页,因为没有客户端应取一个无界结果集。
第 4 步 — 核心服务
平台被分解成聚焦的微服务,每个拥有自己的数据存储。服务读时经 API 网关同步通信、状态变更时经 Kafka 异步通信——绝不伸进另一个服务的数据库。
- 用户服务——认证(OAuth2/JWT)、资料、地址。
- 店铺服务——商家店铺创建和设置。
- 商品服务——目录 CRUD、属性、媒体引用。
- 搜索服务——Elasticsearch 驱动的全文和分面搜索。
- 可服务性服务(Serviceability)——按购买资格(地区、合法性、可用性)过滤商品。
- 购物车服务——Redis 支撑、带 TTL 库存持有的购物车。
- 库存服务——权威库存计数和预留。
- 定价服务——动态定价、促销、优惠券。
- 订单服务——订单生命周期状态机,事务真相来源。
- 支付服务——包装外部网关(Stripe/PayPal),处理幂等和对账。
- 推荐服务——ML 驱动的个性化建议。
- 通知服务——email、SMS、push。
第 5 步 — 数据存储决策
存储选择由每个服务的访问模式和一致性需求驱动。没有单个数据库适合每个负载——多语言持久化正是重点。
| 数据类型 | 存储 | 理由 |
|---|---|---|
| 用户、订单、店铺 | SQL (RDBMS) | 金融交易和结构化关系数据需要 ACID |
| 商品目录 | NoSQL(文档) | 商品有异构属性集;文档存储避免大量 null 的 schema |
| 历史订单 | Cassandra | 横向可扩展、高写吞吐;适合追加重的归档 |
| 购物车持有 | Redis (TTL) | ~10 分钟 TTL 临时预留库存而不永久阻塞 |
| 搜索索引 | Elasticsearch | 规模化的全文搜索、模糊匹配、分面过滤 |
| 媒体 | 对象存储 + CDN | PB 级 blob 服务到用户附近,挡在 DB 外 |
为什么商品用文档存储
笔记本有 CPU、RAM 和屏幕尺寸;T 恤有尺码和颜色;书有 ISBN 和页数。把这建模在单个关系表里产生要么一片可空列、要么一个笨拙的 entity-attribute-value schema。文档存储(MongoDB、DynamoDB)让每个商品恰好携带它需要的属性,且目录压倒性读多、无跨行事务——完美的 NoSQL 契合。
第 6 步 — 数据模型
订单和库存表住在 SQL,因为它们需要事务。一个简化 schema:
CREATE TABLE orders (
id BIGINT PRIMARY KEY,
user_id BIGINT NOT NULL,
status VARCHAR(20), -- PENDING|PAID|SHIPPED|...
total_cents BIGINT NOT NULL,
idempotency_key VARCHAR(64) UNIQUE,
created_at TIMESTAMP,
updated_at TIMESTAMP
);
CREATE TABLE inventory (
product_id BIGINT PRIMARY KEY,
available INT NOT NULL, -- 在库减预留
reserved INT NOT NULL,
version INT NOT NULL -- 乐观锁
);idempotency_key UNIQUE 约束是使重试结账在数据库级别安全的东西:第二次插入只是唯一性检查失败,服务返回已创建的订单。库存上的 version 列支持乐观并发控制,下面覆盖。
第 7 步 — 结账管道
结账是最关键——也最复杂——的流程。关键设计洞见是用 Kafka 把面向用户的确认与下游订单处理链解耦。用户得到即时确认;库存扣减、支付扣款、通知派发和履约启动异步发生。
用户点"购买"
→ 购物车服务校验 TTL 持有仍活跃
→ 订单服务写一个 PENDING 订单到 SQL(幂等键)
→ 发布 OrderCreated 到 Kafka
├── 库存服务: 把持有 → 永久扣减
├── 支付服务 (Stripe/PayPal): 扣卡
│ └── webhook 回调翻转订单 PAID / FAILED
├── 通知服务: 发确认
└── 推荐服务: 记录购买信号跨服务一致性:Saga 模式
单次结账触及订单、库存和支付服务——三个数据库,无分布式事务。标准答案是一个 Saga:一系列本地事务,各发布一个触发下一个的事件,失败时带补偿动作。若扣减库存后支付被拒,一个 PaymentFailed 事件驱动库存服务释放预留、订单服务把订单标 CANCELLED。这用原子性换可用性和最终一致——对一个必须在高峰保持运行的系统是正确选择。
两阶段提交给你原子性但在事务期间跨服务持锁,造成协调者瓶颈并在负载下使可用性暴跌。Saga 保持每个服务独立且高可用,代价是写显式补偿逻辑。
订单状态机
订单最好建模为一个显式状态机;这么做防止非法转换,如发货一个未付订单或退款两次。每个转换由一个事件触发且幂等,所以重放一个 Kafka 消息绝不错误推进状态。
PENDING ──paid──▶ PAID ──pack──▶ PACKED ──ship──▶ SHIPPED ──▶ DELIVERED
│ │
└─超时/失败─▶ CANCELLED └─退货──▶ REFUNDED (终态)把 status 存在由应用级检查(或 DB CHECK/触发器)守卫的 SQL 里,使只有 PAID 订单能移到 PACKED,且 CANCELLED/REFUNDED 是终态。状态字段加 updated_at 时间戳也给支持和分析每个订单旅程的干净审计轨迹。
第 8 步 — 库存与超卖问题
电商最难的正确性问题是购物车到购买的间隙。加入购物车时扣库存,你为放弃购物车的用户阻塞销售;只在结账时扣,你冒高需求突发期间超卖风险。选的中间地带是一个带 TTL(~10 分钟)的 Redis 持有:加入购物车时软预留库存、成功结账时永久扣减,过期持有自动释放。
防止并发超卖
当 10,000 个买家争抢 100 个单位,两个写绝不能都越过零成功。两个机制:
- 乐观锁——读带
version的行,然后UPDATE ... WHERE version = :v;若零行更新,别人赢了——重试。争抢通常低时很好。 - 原子递减——一个 Redis
DECR(或一个条件 SQLUPDATE ... WHERE available > 0)使检查并递减成为单个原子步骤。最适合像闪售这样的极致单品争抢。
-- 原子、并发下安全:仅当还有库存时成功
UPDATE inventory
SET available = available - 1, reserved = reserved + 1
WHERE product_id = 42 AND available > 0;
-- rows affected = 0 → 售罄,拒绝加入购物车第 9 步 — 支付处理
把卡网络当作外部提供商(Stripe、PayPal、Adyen)——你几乎从不想自己做 PCI-DSS Level 1。支付服务是它周围一个薄、谨慎的包装:
- 幂等键——每次扣款尝试传一个唯一键,使超时后重试绝不双重扣款;提供商去重。
- webhook 驱动状态——绝不从同步响应假设成功;权威的
charge.succeeded/charge.failedwebhook 翻转订单状态。验证 webhook 签名。 - 对账——一个每晚作业把你的订单与提供商的结算报告比较,以抓住掉落的 webhook 和卡住的 PENDING 订单。
若扣款成功但 webhook 丢失会怎样?订单卡在 PENDING,客户的钱被取了。对账加一个超时后的"查询扣款状态"回退是安全网——这正是面试官探查的失败模式。
第 10 步 — 搜索与发现
商品和店铺更新经变更数据捕获(CDC)流入 Elasticsearch 集群:主数据库发出变更事件,一个 CDC 连接器(如 Debezium)把它们发布到 Kafka,Kafka 喂搜索索引器。这让索引保持最终一致而不把写延迟耦合到索引——并避免双写陷阱。
搜索服务处理模糊匹配、同义词和 type-ahead。可服务性服务随后在结果返回前按请求用户的地区和购买资格过滤它们。排序混合文本相关性与业务信号(热度、转化率、利润)。
双写(应用同时写 DB 和 Elasticsearch)在一个写失败的那一刻分歧——现在你的搜索显示不存在的商品或隐藏存在的。CDC 使数据库成为单一真相来源、索引成为它变更日志的下游、可重放投影。
第 11 步 — 为高峰流量扩展
闪购和季节性高峰(双 11、黑五)能把流量尖峰提数个数量级。逐层防御:
- CDN + 边缘缓存——静态资源甚至可缓存的商品页服务到用户附近。
- 多层缓存——目录和热门商品读前的 Redis;带合理 TTL 的 cache-aside。100:1 读比意味缓存命中承载大部分流量。
- 读副本——把读扇到副本;写保持在主库。
- 数据库分片——按
user_id分区订单、按product_id分区目录,使没有单节点成瓶颈。 - Kafka 作减震器——异步管道缓冲结账突发,使订单后端按自己节奏排干而非倾倒。
- 限流与负载卸除——保护平台免受滥用客户端和真实踩踏;为限量售卖把用户排进虚拟候车室。
- 自动扩缩——无状态服务按 CPU/延迟触发横向扩展。
商家处理模型
- 大企业(批拉)——Apache Airflow 调度批量库存/目录拉取;对高量定时更新更好。
- 中小企业(推模型)——商品或订单事件时立即推送变更以求新鲜。
深入缓存策略
100:1 读写比下,缓存是杠杆最高的单项优化。默认模式是 cache-aside:应用先查 Redis、未命中时回退到数据库、填充缓存。难的部分不是 happy path 而是失败模式:
- 失效——商品或价格更新时,发布一个事件驱逐或刷新缓存条目。结账时显示陈旧价格是真实的收入甚至法律风险,所以价格用短 TTL 缓存并急切失效。
- 缓存击穿——热 key 过期时,数千请求同时未命中并猛敲数据库。用随机 TTL 抖动、一个单飞互斥(只一个请求重建条目),或过期前后台 refresh-ahead 缓解。
- 热点 key——一个病毒商品能饱和一个 Redis 分片。跨分片复制热 key 或在 Redis 前加一个小进程内缓存吸收尖峰。
- 缓存什么——商品详情页、分类列表、搜索结果(短 TTL);绝不缓存权威库存计数或订单状态,它们必须总被强读。
深入分片策略
单个主库无法持有 5 亿商品或吸收峰值订单写,所以横向分区——而选好分片键是全部关键:
- 订单——按
user_id分片,使一个用户的完整历史住一个分片、常见的"我的订单"读保持单分片。按order_id分片会把一个用户的订单散到节点。 - 目录——按
product_id哈希分片以均匀分布、无热分区。 - 跨分片查询——"本月某区域所有订单"必须扇出到每个分片并合并,慢;把这类分析查询路由到 OLAP/数仓副本而非 OLTP 路径。
- 重分片——用一致性哈希或一个查找/目录服务,使加容量移动最少数据。朴素取模分片在分片数变化时重洗几乎每行。
第 12 步 — 可靠性与容错
99.99% 可用性下每个依赖最终都会失败;设计必须优雅降级而非崩溃。
- 复制 + 多 AZ——每个数据存储跨可用区带副本运行;主丢失时自动故障转移。
- 熔断器——推荐服务宕时,首页回退到一个非个性化的"热门商品" feed 而非报错。
- 幂等消费者——Kafka 保证至少一次投递,所以每个消费者按事件 ID 去重;重处理一个
OrderCreated不能扣两次库存。 - 死信队列——反复失败的事件被停放检查而非阻塞分区。
- 优雅降级——搜索宕?服务缓存的分类页。定价宕?服务最后已知价格。保持购买按钮活着。
可观测性
没有看进系统内部你无法在 99.99% 运作。倚靠三大支柱:
- 指标——每服务 RED(Rate、Errors、Duration)加业务指标(订单/分钟、支付成功率、购物车放弃)在 Prometheus/Grafana,每服务有仪表盘。
- 分布式追踪——跨网关 → 订单 → 库存 → 支付传播的 trace ID 把一个"结账慢"报告变成你能指出的确切 span。
- 结构化日志与告警——按
orderId/userId为键的集中日志便于 grep,并在 SLO 燃尽(如支付成功率 < 99%、p99 延迟 > 300 ms)而非原始资源用量上告警。
安全、欺诈与滥用
钱吸引攻击者,所以防御必须跨栈分层而非坐在单个门:
- 认证 / 授权——OAuth2 配短命 JWT 访问令牌加刷新令牌;商家和管理 API 带独立 scope,使泄露的客户令牌碰不到目录。
- 限流——网关处每用户和每 IP 令牌桶钝化撞库、抓取和意外客户端重试风暴。
- 欺诈评分——速度检查(短窗口内许多订单或许多卡)、设备指纹和一个 ML 风险分把可疑订单路由到履约前的持有/审查队列。
- 售卖的 bot 防御——限量闪购吸引 bot;结合 CAPTCHA、虚拟候车室和每账号购买限制。
- PCI 范围最小化——绝不存原始卡数据;经支付提供商 tokenize,使泄露不能漏卡号。
退货、退款与多区域
购后流程在面试里常被跳过但是真实范围。一次退货产生一个逆向物流任务;收到商品时,一次退款重入支付服务(又是幂等、又是 webhook 确认)并重新入库。退款是它们自己的小状态机,且必须像扣款一样对照提供商的结算报告对账。
对全球受众,一个多区域部署削减延迟并提供灾难恢复。目录和搜索只读复制到每个区域,而订单通常被钉到用户的主区域以保持事务路径简单,带异步跨区域复制做 DR。强全局一致昂贵且很少值得——大多数设计接受区域所有权加最终全局复制,只在区域宕机时故障转移到另一区域。
第 13 步 — ML 与推荐
用户行为信号——搜索查询、加入购物车、愿望单保存和完成购买——经 Kafka 捕获并喂进 Spark Streaming 做近实时分析。推荐服务用它们做:
- 用户分段(回归模型、KNN 聚类)。
- 个性化首页和"买了又买"模块。
- 动态定价和促销定向。
- 喂库存规划的需求预测。
每个表携带 created_at / updated_at 列,身兼两职:调试生产问题和为这些模型提供时间特征。
关键取舍
| 决策 | 选择 | 接受的取舍 |
|---|---|---|
| 订单一致性 | 强(SQL + ACID) | 比 NoSQL 更低写吞吐,由分片缓解 |
| 目录与搜索 | 最终(CDC) | 新商品可能需数秒出现在搜索 |
| 跨服务事务 | Saga | 必须写显式补偿逻辑;无全局回滚 |
| 库存持有 | Redis TTL | 持有后放弃的商品短暂不可用的小窗口 |
| 结账路径 | 经 Kafka 异步 | 订单在支付确认前已"下单";状态稍后更新 |
电商系统设计从根本上关于隔离一致性域:钱和订单用 SQL + ACID,灵活目录用文档存储,归档规模用 Cassandra,Kafka 把结账关键路径与所有下游效果解耦。Redis TTL 购物车持有是超卖-vs-损失销售取舍的经典答案,Saga 模式是你不用分布式事务保持正确性的方式。
闪购期间怎么防止超卖?Redis TTL 持有(~10 分钟)在加入购物车时软预留;只在确认结账时经原子条件递减永久扣减;过期持有自动释放。
为什么结账和支付间用 Kafka?把面向用户延迟与下游工作解耦——即时订单确认,同时库存、支付和通知异步进行,Kafka 也缓冲突发。
不用 2PC 怎么保持三个服务一致?Saga 模式——由事件串联的本地事务,失败时带补偿动作(释放库存、取消订单)。
为什么 CDC 进 Elasticsearch 而非双写?CDC 让索引作为可重放投影与 DB 一致;双写若索引写失败就分歧。
怎么避免给客户双重扣款?扣款调用上的幂等键加 webhook 驱动状态和每晚对账。